1.XMemcached是什么
XMemcached是众多Memcached Client中的后起之秀,而且还是一个Chinese主导的.写这篇Blog的目的就是研究下这个Memcached Client的代码,顺便研究下传说中的一致性Hash.
XMemcached项目:https://code.google.com/p/xmemcached/
源代码:https://github.com/killme2008/xmemcached
使用文档:http://blog.sina.com.cn/s/blog_6094008a0102v6gj.html
特点:
(1).支持所有的Memcached文本协议(text based protocols)和二进制协议(二进制协议从1.2.0开始支持);
(2).支持分布式的Memcached,包括标准Hash和一致性哈希策略;
(3).支持JMX,从而允许使用者监控和控制XMemcached Client的行为;同时可以修改优化参数,动态添加或者删除服务器;
(4).支持待权重的服务器配置;
(5).支持连接池,使用Java的nio,对同一个Memcached服务器使用者能够创建更多的连接;
(6).支持故障模式和备用节点;
(7).支持和Spring框架和hibernate-memcached的整合;
(8).高性能;
(9).支持和kestrel(一个Scala实现的MQ)和TokyoTyrant的对话;
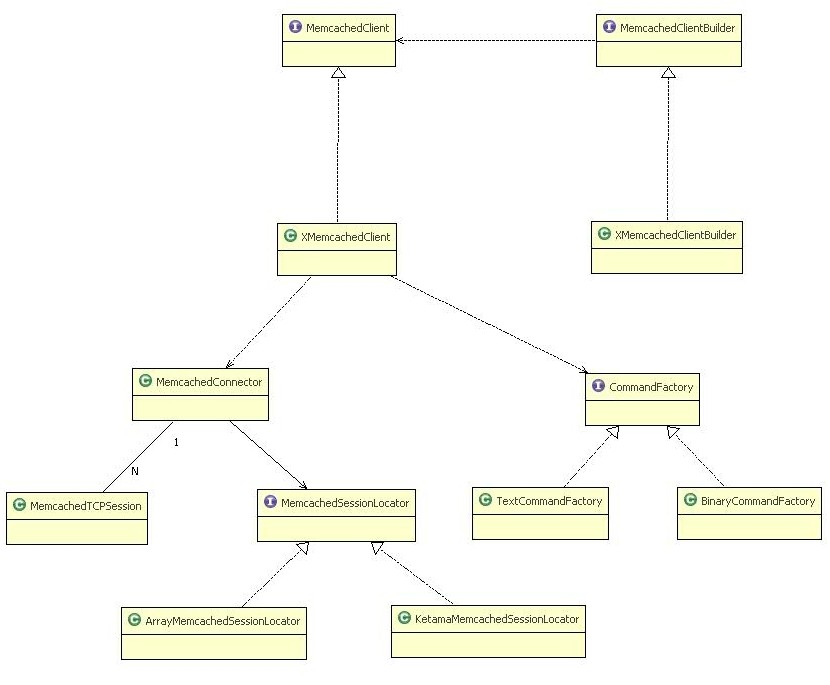
2.XMemcached的类图
XMemcached的类图(几个主要的类):
3.XMemcached的示例
源代码中自带了例子,我们分析一个SimpleExample.java:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
| public class SimpleExample {
public static void main(String[] args) {
if (args.length < 1) {
System.err.println("Useage:java SimpleExample [servers]");
System.exit(1);
}
MemcachedClient memcachedClient = getMemcachedClient(args[0]);
if (memcachedClient == null) {
throw new NullPointerException("Null MemcachedClient,please check memcached has been started");
}
try {
// add a,b,c
System.out.println("Add a,b,c");
memcachedClient.set("a", 0, "Hello,xmemcached");
memcachedClient.set("b", 0, "Hello,xmemcached");
memcachedClient.set("c", 0, "Hello,xmemcached");
// get a
String value = memcachedClient.get("a");
System.out.println("get a=" + value);
System.out.println("delete a");
// delete a
memcachedClient.delete("a");
// reget a
value = memcachedClient.get("a");
System.out.println("after delete,a=" + value);
System.out.println("Iterate all keys...");
// iterate all keys
KeyIterator it = memcachedClient.getKeyIterator(AddrUtil.getOneAddress(args[0]));
while (it.hasNext()) {
System.out.println(it.next());
}
System.out.println(memcachedClient.touch("b", 1000));
} catch (MemcachedException e) {
System.err.println("MemcachedClient operation fail");
e.printStackTrace();
} catch (TimeoutException e) {
System.err.println("MemcachedClient operation timeout");
e.printStackTrace();
} catch (InterruptedException e) {
// ignore
}
try {
memcachedClient.shutdown();
} catch (Exception e) {
System.err.println("Shutdown MemcachedClient fail");
e.printStackTrace();
}
}
public static MemcachedClient getMemcachedClient(String servers) {
try {
//默认是Text协议
MemcachedClientBuilder builder = new XMemcachedClientBuilder(AddrUtil.getAddresses(servers));
return builder.build();
} catch (IOException e) {
System.err.println("Create MemcachedClient fail");
e.printStackTrace();
}
return null;
}
}
|
本地先起来两个Memcached实例:
1
2
| /usr/bin/memcached -m 256 -p 11211 -u memcache -l 127.0.0.1 -d
/usr/bin/memcached -m 256 -p 11222 -u memcache -l 127.0.0.1 -d
|
在IDEA下运行,配上运行参数,即Memcached服务器的IP和端口,格式如下(解析代码见AddrUtil.java):
1
| 127.0.0.1:11211 127.0.0.1:11222
|
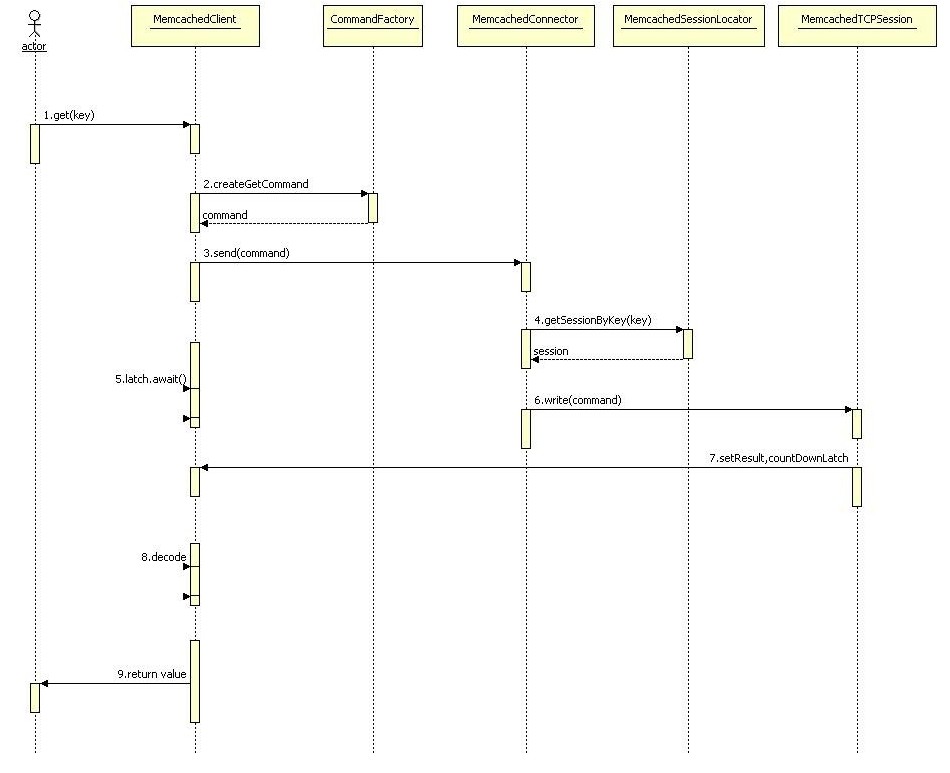
Debug代码,可以发现其运行过程,下面是get的一个运行序列图:
4.XMemcached的分布式实现
memcached虽然称为“分布式”缓存服务器,但服务器端并没有"“分布式”功能.至于memcached的分布式,则是完全由客户端程序库实现的.
4.1 Memcached的分布式是什么意思
这里多次使用了“分布式”这个词,但并未做详细解释.现在开始简单地介绍一下其原理,各个客户端的实现基本相同.
下面假设memcached服务器有node1~node3三台, 应用程序要保存键名为“tokyo”“kanagawa”“chiba”“saitama”“gunma” 的数据.
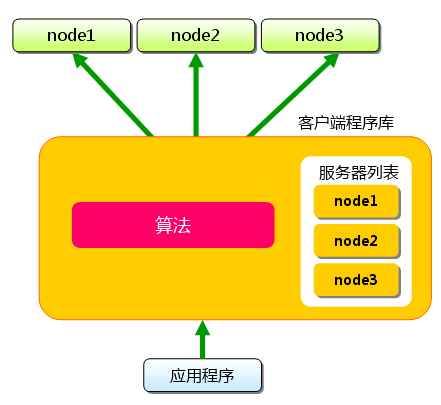
首先向memcached中添加“tokyo”.将“tokyo”传给客户端程序库后, 客户端实现的算法就会根据“键”来决定保存数据的memcached服务器. 服务器选定后,即命令它保存“tokyo”及其值.
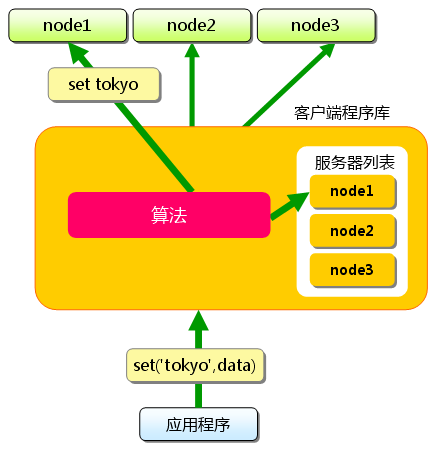
同样,“kanagawa”“chiba”“saitama”“gunma”都是先选择服务器再保存.
接下来获取保存的数据.获取时也要将要获取的键“tokyo”传递给函数库. 函数库通过与数据保存时相同的算法,根据“键”选择服务器. 使用的算法相同,就能选中与保存时相同的服务器,然后发送get命令. 只要数据没有因为某些原因被删除,就能获得保存的值.
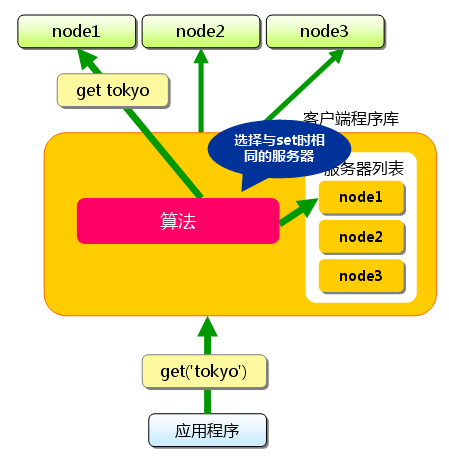
这样,将不同的键保存到不同的服务器上,就实现了memcached的分布式. memcached服务器增多后,键就会分散,即使一台memcached服务器发生故障
无法连接,也不会影响其他的缓存,系统依然能继续运行.
4.2 余数哈希
XMemcached默认使用的是Native Hash,见ArrayMemcachedSessionLocator.java:
1
2
3
4
| public final long getHash(int size, String key) {
long hash = this.hashAlgorighm.hash(key);
return hash % size;
}
|
ArrayMemcachedSessionLocator中使用的hashAlgorighm是HashAlgorithm.NATIVE_HASH,而HashAlgorithm.NATIVE_HASH的hash()函数的实现:
1
2
3
4
5
6
7
| public long hash(final String k) {
long rv = 0;
switch (this) {
case NATIVE_HASH:
rv = k.hashCode();
break;
...
|
即XMemcached的Native Hash就是通常的余数哈希:首先求得字符串的hash值,根据该值除以服务器节点数目得到的余数决定服务器.
根据这种hash方式,上门这几个key分布的服务器如下(三台服务器分别为 0 1 2):
1
2
3
4
5
| tokyo --> 2
kanagawa --> 1
chiba --> 2
saitama --> 1
gunma --> 2
|
优点
简单高效:计算简单,数据的分散性也相当优秀
缺点
当添加或移除服务器时,缓存重组的代价相当巨大. 添加服务器后,余数就会产生巨变,这样就无法获取与保存时相同的服务器, 从而影响缓存的命中率.
下面简单验证这个:首先在3台服务器的情况下将“a”到“z”的键保存到memcached并访问的情况;接下来增加一台memcached服务器;计算缓存命中率;
简单测试代码(忍不住吐槽下java真是一门罗嗦的语言):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
| public class Hash {
/**
* 默认的Hash算法
*/
private static HashAlgorithm hashAlgorithm = HashAlgorithm.NATIVE_HASH;
/**
* Memcached服务器数目
*/
private static final int SERVER_SIZE = 3;
public static void main(String[] args) {
// 初始化
Map<Long, List<String>> itemMap = new HashMap<Long, List<String>>();
for (long i = 0; i < SERVER_SIZE; i++) {
itemMap.put(i, new LinkedList<String>());
}
char letters[] = new char[27];
letters[0] = 'a';
for (int i = 0; i < 26; i++) {
letters[i + 1] = (char) (letters[i] + 1);
long hash = getHash(SERVER_SIZE, String.valueOf(letters[i]));
itemMap.get(hash).add(String.valueOf(letters[i]));
}
for (Map.Entry<Long, List<String>> e : itemMap.entrySet()) {
System.out.println(e.getKey() + " : " + join(e.getValue()));
}
}
public static long getHash(int size, String key) {
long hash = hashAlgorithm.hash(key);
return hash % size;
}
private static String join(final List<String> list) {
StringBuilder builder = new StringBuilder();
for(String s : list) {
builder.append(s + ' ');
}
return builder.toString();
}
}
|
我们得到3台服务器(分别为0,1,2)的时候,26个字母的分布如下:
0 : c f i l o r u x
1 : a d g j m p s v y
2 : b e h k n q t w z
4台服务器(分别为0,1,2,3)的时候,26个字母的分布如下:
0 : d h l p t x
1 : a e i m q u y
2 : b f j n r v z
3 : c g k o s w
根据这两份数据,我们可以得到,加拉一台服务器之后,26个字母只有8个命中了.像这样,添加节点后键分散到的服务器会发生巨大变化.
同样,减少服务器(比如某一台服务器down机),也会导致大量的Miss,基本失去了缓存的作用.
带来的问题就是,在Web应用程序中使用memcached时, 在添加memcached服务器的瞬间缓存效率会大幅度下降,有可能会发生无法提供正常服务的情况.
4.3 一致性哈希(Consistent Hashing)
一致性哈希能够很大程度上(注意不是完全解决)解决余数哈希的增加服务器导致缓存失效的问题.
4.3.1 一致性哈希原理
Consistent Hashing如下所示:首先求出memcached服务器(节点)的哈希值,
并将其配置到0~2SUP(32)的圆(continuum)上. 然后用同样的方法求出存储数据的键的哈希值,并映射到圆上. 然后从数据映射到的位置开始顺时针查找,将数据保存到找到的第一个服务器上. 如果超过2SUP(32)仍然找不到服务器,就会保存到第一台memcached服务器上.
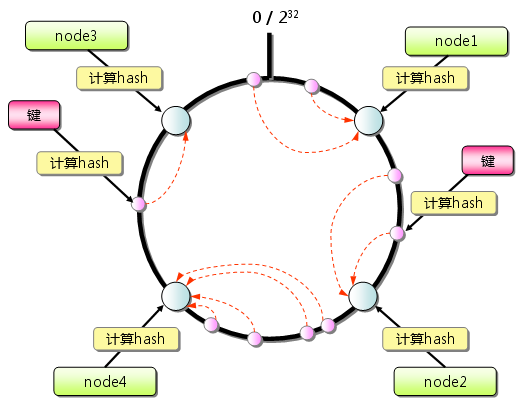
从上图的状态中添加一台memcached服务器.余数分布式算法由于保存键的服务器会发生巨大变化 而影响缓存的命中率,但Consistent Hashing中,只有在continuum上增加服务器的地点逆时针方向的 第一台服务器上的键会受到影响.
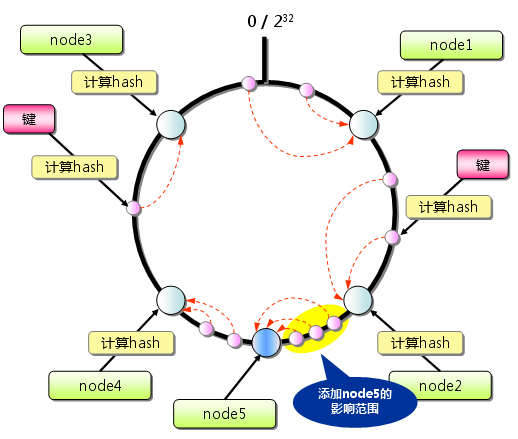
因此,Consistent Hashing最大限度地抑制了键的重新分布. 而且,有的Consistent Hashing的实现方法还采用了虚拟节点的思想. 使用一般的hash函数的话,服务器的映射地点的分布非常不均匀. 因此,使用虚拟节点的思想,为每个物理节点(服务器) 在continuum上分配100~200个点.这样就能抑制分布不均匀, 最大限度地减小服务器增减时的缓存重新分布.
4.3.2 虚拟节点
一致性哈希算法在服务节点太少时,容易因为节点分部不均匀而造成数据倾斜问题.例如我们的系统中有两台 server,其环分布如下:
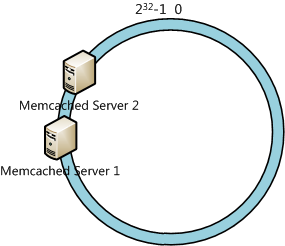
此时必然造成大量数据集中到Server 1上,而只有极少量会定位到Server 2上.为了解决这种数据倾斜问题,一致性哈希算法引入了虚拟节点机制.
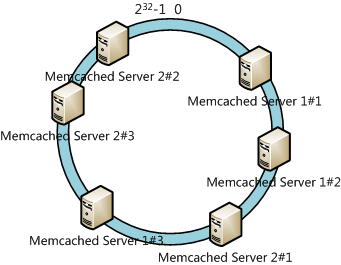
虚拟节点(virtual node)是实际节点(服务器)在 hash 空间的复制品,一个实际节点(服务器)对应了若干个虚拟节点,这个对应个数也称为为复制个数,虚拟节点在 hash 环中以hash值排列.
例如为上面的每台服务器设置三个虚拟节点:
在实际应用中,一个物理节点对应多少的虚拟节点才能达到比较好的均衡效果,有一个效果图:
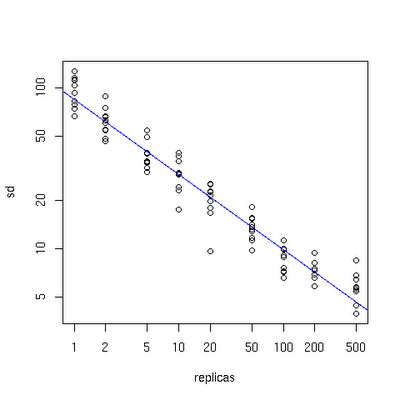
纵轴为物理服务器的数目,横轴为虚拟节点的数目,可以看出,当物理服务器的数量很小时,需要更大的虚拟节点,反之则需要更少的节点,从图上可以看出,在物理服务器有10台时,差不多需要为每台服务器增加100~200个虚拟节点效果比较好.
4.4 XMemcached一致性哈希的实现
XMemcached Client中实现了一致性哈希,见KetamaMemcachedSessionLocator.java,使用的Hash算法是KETAMA HASH算法.
下面主要分析一下KetamaMemcachedSessionLocator.java代码,去掉了一些无关的代码:
4.4.1 根据服务器列表生成Hash环
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
| private final void buildMap(Collection<Session> list, HashAlgorithm alg) {
TreeMap<Long, List<Session>> sessionMap = new TreeMap<Long, List<Session>>();
for (Session session : list) { //遍历每个服务器
String sockStr = null; //根据服务器地址得到的字符串,用于hash
if (this.cwNginxUpstreamConsistent) {
... //生成sockStr
} else {
... //生成sockStr
}
/**
* Duplicate 160 X weight references
*/
int numReps = NUM_REPS; //虚拟节点数目, 默认160
//考虑权重,权重小的服务器最终生成的虚拟节点就少,数据打到这个服务器的概率就小
if (session instanceof MemcachedTCPSession) {
numReps *= ((MemcachedSession) session).getWeight();
}
if (alg == HashAlgorithm.KETAMA_HASH) { //一致性Hash
for (int i = 0; i < numReps / 4; i++) {
//计算Hash值,将虚拟节点映射到当前session代表的服务器
byte[] digest = HashAlgorithm.computeMd5(sockStr + "-" + i);
for (int h = 0; h < 4; h++) {
long k = (long) (digest[3 + h * 4] & 0xFF) << 24 | (long) (digest[2 + h * 4] & 0xFF) << 16
| (long) (digest[1 + h * 4] & 0xFF) << 8 | digest[h * 4] & 0xFF;
this.getSessionList(sessionMap, k).add(session);
}
}
} else {
...
}
}
this.ketamaSessions = sessionMap;
this.maxTries = list.size();
}
private List<Session> getSessionList(TreeMap<Long, List<Session>> sessionMap, long k) {
List<Session> sessionList = sessionMap.get(k);
if (sessionList == null) {
sessionList = new ArrayList<Session>();
sessionMap.put(k, sessionList);
}
return sessionList;
}
|
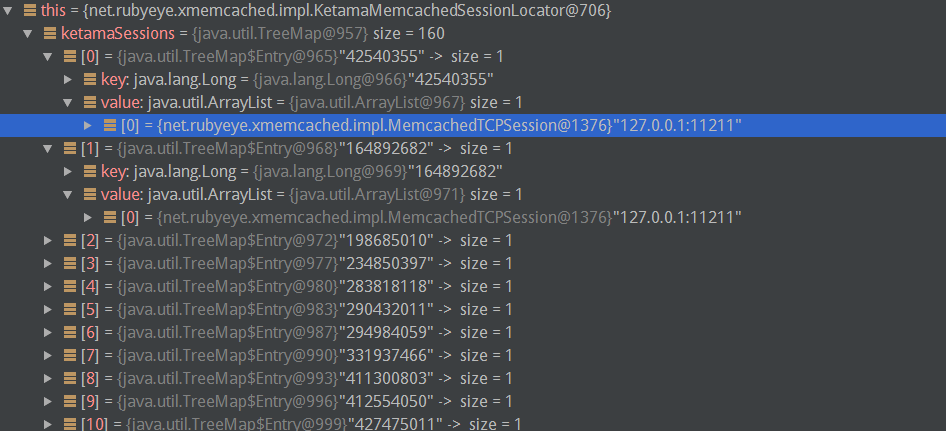
buildMap的结果就是在0-232这个圈上生成一些列的虚拟节点,每个虚拟节点都指向一个真实服务器.
例如本机只开一个服务器情况下,没有设置权重,会生成160个虚拟节点,每个虚拟节点都指向中一台服务器:
 4.4.2 对Key做Hash
4.4.2 对Key做Hash
做get或者set的时候,首先都会通过key找到服务器:
1
| public Session getSessionByKey(final String key);
|
其实现代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
| //通过key找真实到服务器
public final Session getSessionByKey(final String key) {
if (this.ketamaSessions == null || this.ketamaSessions.size() == 0) {
return null;
}
long hash = this.hashAlg.hash(key); //计算key的Hash值
Session rv = this.getSessionByHash(hash); //通过Hash值找服务器
int tries = 0;
while (!this.failureMode && (rv == null || rv.isClosed())
&& tries++ < this.maxTries) {
hash = this.nextHash(hash, key, tries);
rv = this.getSessionByHash(hash);
}
return rv;
}
public final Session getSessionByHash(final long hash) {
TreeMap<Long, List<Session>> sessionMap = this.ketamaSessions;
if (sessionMap.size() == 0) {
return null;
}
Long resultHash = hash;
if (!sessionMap.containsKey(hash)) {
//下面的逻辑是找到大于hash值的第一个虚拟节点(即ceiling)
//Java 1.6使用ceilingKey可以实现,为兼容jdk5,使用tailMap,tailMap为所有大于hash值的虚拟节点
SortedMap<Long, List<Session>> tailMap = sessionMap.tailMap(hash);
if (tailMap.isEmpty()) {//没有比hash值大的节点,则取第一个虚拟节点
resultHash = sessionMap.firstKey();
} else {
resultHash = tailMap.firstKey();//取tailMap第一个,即最大于hash值最小节点
}
}
List<Session> sessionList = sessionMap.get(resultHash);
if (sessionList == null || sessionList.size() == 0) {
return null;
}
int size = sessionList.size();
return sessionList.get(this.random.nextInt(size));
}
|
这里调试时候key是'a',其Hash值是3111502092:
 getSessionByHash的逻辑其实就是在Hash环上找第一个大于key对应hash值的虚拟节点,通过虚拟节点找到真实服务器.
getSessionByHash的逻辑其实就是在Hash环上找第一个大于key对应hash值的虚拟节点,通过虚拟节点找到真实服务器.
这里的tailMap即为大于3111502092的虚拟节点,如下:
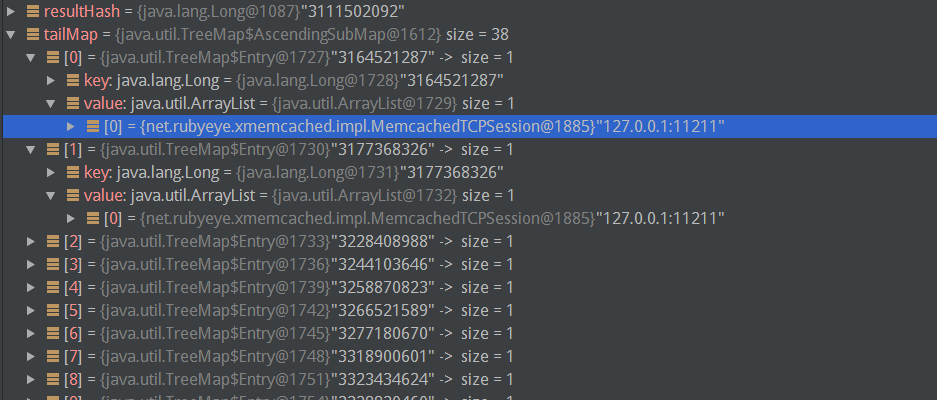
因此我们要找的虚拟节点就是3164521287对应的虚拟节点,其服务器指向的是127.0.0.1:11211.因此当前key(这里为'a')的请求被打到这台服务器上.
4.5 使用XMemcached的一致性哈希
默认情况下XMemcached使用的是余数哈希,如下使用一致性哈希:
1
2
3
4
| MemcachedClientBuilder builder = new XMemcachedClientBuilder(AddrUtil.getAddresses(servers));
// 设置使用一致性hash
builder.setSessionLocator(new KetamaMemcachedSessionLocator());
return builder.build();
|