根据上篇文章,我们大致知道Lucene创建索引和搜索的一个过程:
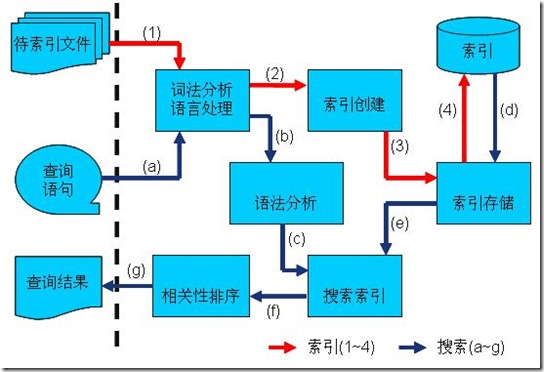
这里主要分析一下Lucene的代码结构,包括理由Lucene API实现一个简单建立索引和搜索的小例子.
由于我们的服务器上crate是基于Lucene 4.10.3版本.所以我这里采用的Lucene版本也是4.10版本,小版本是4.10.4,是Lucene 4的最后一个版本,大约2014年9月推出,还比较新鲜.目前已经到了5.3版本.
1.源码结构
首先看一下Lucene的源码结构,Lucene-core主要代码包结构如下:
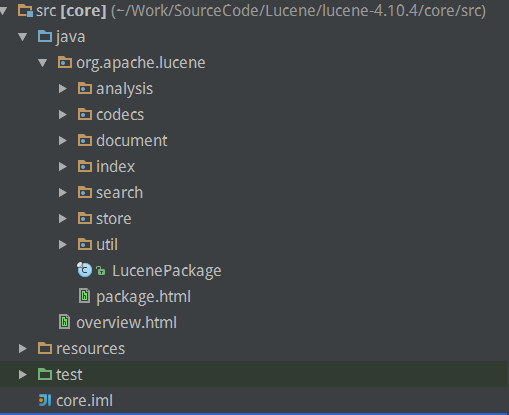
每个包下面都有package.html文件介绍包的作用.各个包的作用如下:
1.analysis
分词模块,包含将文本转化为可索引化/可搜索化的词元(convert text into indexable/searchable tokens)的API和实现.包括org.apache.lucene.analysis.Analyzer和其相关类.
2.codecs
包含自定义底层索引的编码和索引结构的模块,还包括索引的压缩,索引版本管理等.
3.document
定义了被索引和搜索内容的用户层面的逻辑定义,就是我们熟悉的Document,各种类型的Filed及其属性定义等.同事也提供了一下org.apache.lucene.document.Document和org.apache.lucene.index.IndexableField相关的工具类.
4.index
包含了索引维护(创建,更新,删除)和访问(读)的逻辑.包括我们熟悉的IndexReader,IndexWriter等.
5.search
索引的搜索.包括相似度的定义(similarities包),权重计算,文档评分计算,布尔模型,搜索结果搜集等逻辑.
6.store
索引底层二进制数据的读写,包括索引文件的Buffered的流的实现等,还包括一些限流策略的实现(RateLimiter)等.
7.util
工具类,如排序器,数学工具类,优先级队列等工具的实现等.
包基本上和本文开头的图对应起来,其中的QueryParser再Lucene4中是一个单独的jar包:
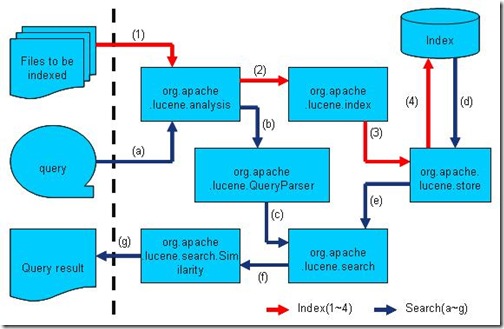
2.Lucene使用Demo
首先上一个Lucene的简单的Demo,基本上是参考官网提供的Demo,自己手动修改了点,作用就是索引一个目录下的文本文件,在此基础上提供搜索服务.其中Indexer用于创建索引,Searcher作为搜索入口,接受用户输入的Query词并执行搜索.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
| /**
* 创建索引
*
* @author: xiaobaoqiu Date: 15-9-8 Time: 下午4:04
*/
public final class Indexer {
public static void main(String[] args) {
indexDocs(CommonConfig.SOURCE_FILE_DIR, CommonConfig.INDEX_FILE_DIR, true);
}
/**
* 构建磁盘索引
*
* @param dirPath 原始文件
* @param indexPath 索引文件存放路径
* @param create 创建or更新
*/
public static void indexDocs(String dirPath, String indexPath, boolean create) {
try {
Directory dir = FSDirectory.open(new File(indexPath));
Analyzer analyzer = new StandardAnalyzer(Version.LUCENE_4_10_0);
IndexWriterConfig iwc = new IndexWriterConfig(Version.LUCENE_4_10_0, analyzer);
if (create) {
iwc.setOpenMode(IndexWriterConfig.OpenMode.CREATE);
} else {
iwc.setOpenMode(IndexWriterConfig.OpenMode.CREATE_OR_APPEND);
}
IndexWriter writer = new IndexWriter(dir, iwc);
doIndexDocs(writer, new File(dirPath));
System.out.println("Build index finished...");
writer.close();
}catch (IOException ioe) {
//do something...
}
}
static void doIndexDocs(IndexWriter writer, File file) throws IOException {
if (!file.canRead()) {
System.out.println("文件不可读:" + file.getAbsolutePath());
return;
}
//文件夹则索引文件夹下的索引文件
if (file.isDirectory()) {
String[] files = file.list();
if (files != null) {
for (int i = 0; i < files.length; i++) {
doIndexDocs(writer, new File(file, files[i]));
}
}
} else {
doIndexFile(writer, file);
}
}
/**
* 索引一个文件
*
* @param writer
* @param file
*/
private static void doIndexFile(IndexWriter writer, File file) throws IOException{
//单个文件
FileInputStream fis;
try {
fis = new FileInputStream(file);
} catch (FileNotFoundException fnfe) {
//do nothing
return;
}
try {
// 创建一个新的空的Document
Document doc = new Document();
//文件路径字段
doc.add(new StringField(CommonConfig.PATH_FIELD_NAME, file.getPath(), Field.Store.YES));
//文件最后修改时间字段
doc.add(new LongField(CommonConfig.MODIFIED_FIELD_NAME, file.lastModified(), Field.Store.NO));
//文件内容,不存储原始串
doc.add(new TextField(CommonConfig.CONTENTS_FIELD_NAME, new BufferedReader(new InputStreamReader(fis, StandardCharsets.UTF_8))));
//新建索引 or 更新索引
if (writer.getConfig().getOpenMode() == IndexWriterConfig.OpenMode.CREATE) {
writer.addDocument(doc);
} else {
writer.updateDocument(new Term("path", file.getPath()), doc);
}
} finally {
fis.close();
}
}
}
/**
* 查询索引
* 接受用户输入作为Query词
*
* @author: xiaobaoqiu Date: 15-9-8 Time: 下午4:09
*/
public final class Searcher {
public static void main(String[] args) throws Exception {
search(CommonConfig.INDEX_FILE_DIR, CommonConfig.CONTENTS_FIELD_NAME);
}
public static void search(String indexPath, String field) throws Exception {
IndexReader reader = DirectoryReader.open(FSDirectory.open(new File(indexPath)));
IndexSearcher searcher = new IndexSearcher(reader);
Analyzer analyzer = new StandardAnalyzer(Version.LUCENE_4_10_0);
QueryParser parser = new QueryParser(Version.LUCENE_4_10_0, field, analyzer);
//接受用户输入
BufferedReader in = new BufferedReader(new InputStreamReader(System.in, StandardCharsets.UTF_8));
String queryString = null;
while (StringUtils.isNotEmpty(queryString = in.readLine())) {
Query query = parser.parse(queryString.trim());
doSearch(searcher, query);
}
reader.close();
}
public static void doSearch(IndexSearcher searcher, Query query) throws IOException {
// 搜索 CommonConfig.SEARCH_MAX_ITEM_COUNT 个数据
TopDocs results = searcher.search(query, CommonConfig.SEARCH_MAX_ITEM_COUNT);
ScoreDoc[] hits = results.scoreDocs;
int numTotalHits = results.totalHits;
System.out.println(numTotalHits + " total matching documents");
if (ArrayUtils.isEmpty(hits)) return;
for (ScoreDoc hit : hits) {
System.out.println();
Document hitDoc = searcher.doc(hit.doc);
System.out.println(CommonConfig.PATH_FIELD_NAME + " = " + hitDoc.get(CommonConfig.PATH_FIELD_NAME) +
"\n" + CommonConfig.MODIFIED_FIELD_NAME + " = " + hitDoc.get(CommonConfig.MODIFIED_FIELD_NAME) +
"\n" + CommonConfig.CONTENTS_FIELD_NAME + " = " + hitDoc.get(CommonConfig.CONTENTS_FIELD_NAME));
}
}
}
|
输入的文件及生成的索引:
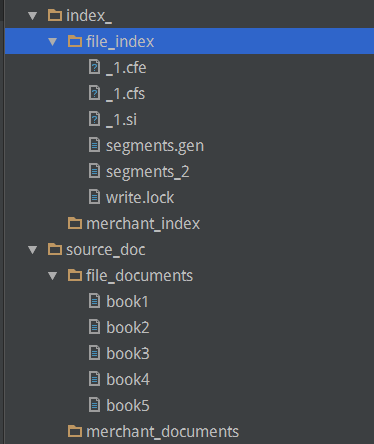
建立索引的基本过程如下:
1.FSDirectory定义索引文件存放目录
2.选择分词使用的Analyzer.
3.选择索引文件版本信息Version,将其和Analyzer组成IndexWriterConfig.
4.利用IndexWriterConfig生成一个IndexWriter,用于索引文件的变更;
5.根据原始文件生成一些列的Document,每个文档中包含多个Field,设置每个Field是否分词,释放存储等属性;
6.使用IndexWriter将文档写入索引文件.
搜索的基本过程如下:
1.根据索引文件的目录生成一个IndexReader,将索引文件读到内存中.
2.生成一个IndexSearcher用于搜索;
3.选择一个分词器;
4.定义用户输入Query的解析器QueryParser;
5.接受用户输入,执行搜索过程,得到搜索结果用TopDocs表示,其中包含了命中文档的数目以及命中文档的id集合;
6.根据文档id获取对应的文档,从文档中获取各个Field信息;
2.1 主要类
首先介绍一下其中涉及到的主要的类:
FSDirectory
Lucene文件操作都是通过Directory实现,其中有一个比较特殊的方法sync,用来保证任何对文件的写都能够得到永久保存。Lucene使用这个来保证正确提交索引数据变更,也能够防止机器或者操作系统级别的错误影响(corrupting)索引数据.
Analyzer,StandardAnalyzer
- Version
- IndexWriterConfig
- IndexWriter
- Document
- StringField,LongField,TextField
- IndexReader,DirectoryReader
- IndexSearcher
- QueryParser
- Query
- TopDocs
- ScoreDoc
3.建立索引流程
4.搜索流程