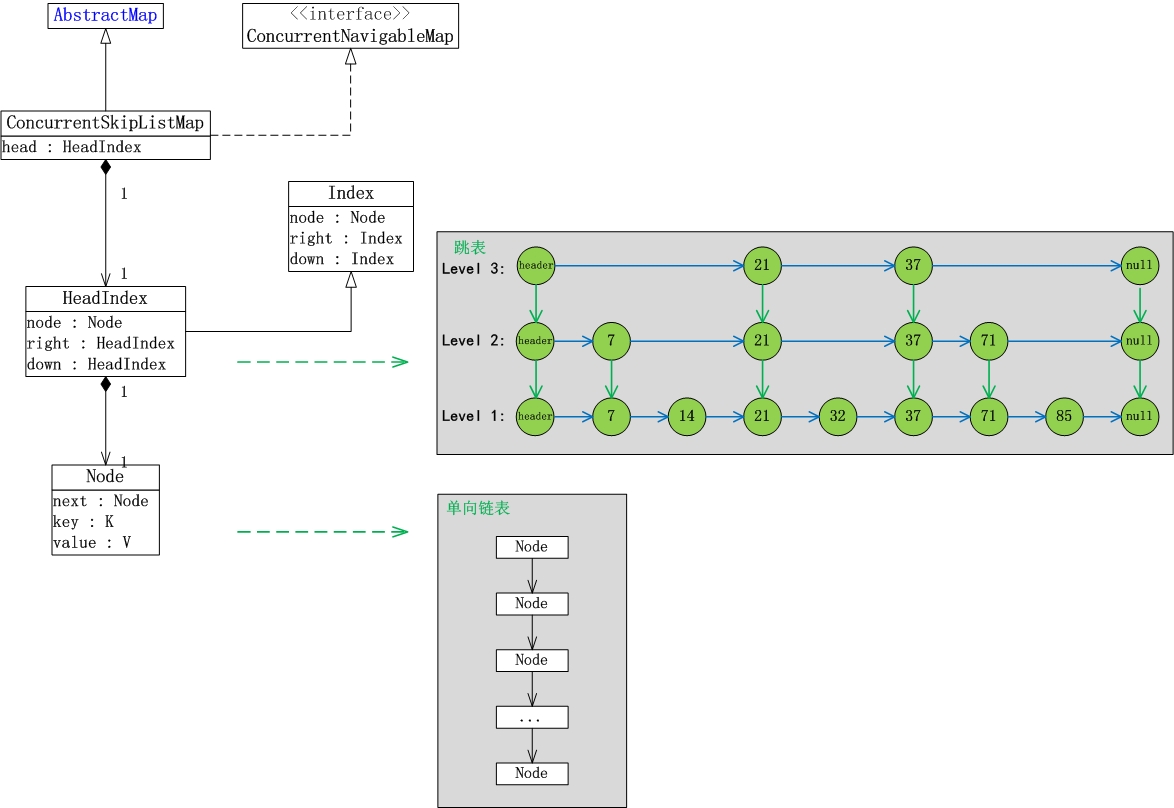
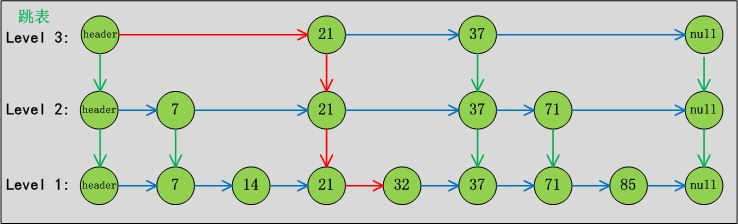
publicVput(Kkey,Vvalue){if(value==null)thrownewNullPointerException();returndoPut(key,value,false);}privateVdoPut(Kkkey,Vvalue,booleanonlyIfAbsent){Comparable<?superK>key=comparable(kkey);for(;;){Node<K,V>b=findPredecessor(key);//找到key的前继节点Node<K,V>n=b.next;//key的前继节点的后继节点,即 插入节点 的“后继节点”for(;;){if(n!=null){Node<K,V>f=n.next;//如果两次获得的b.next不是相同的Node,就跳转到外层循环,重新遍历。if(n!=b.next)// inconsistent readbreak;;Objectv=n.value;//当n的值为null(意味着其它线程删除了n);此时删除b的下一个节点,然后跳转到”外层for循环“,重新遍历。if(v==null){// n is deletedn.helpDelete(b,f);break;}// 如果其它线程删除了b;则跳转到”外层for循环“,重新获得b和n后再遍历。if(v==n||b.value==null)// b is deletedbreak;intc=key.compareTo(n.key);if(c>0){b=n;n=f;continue;}if(c==0){if(onlyIfAbsent||n.casValue(v,value))return(V)v;elsebreak;// restart if lost race to replace value}// else c < 0; fall through}// 新建节点(对应是“要插入的键值对”)Node<K,V>z=newNode<K,V>(kkey,value,n);if(!b.casNext(n,z))// 设置“b的后继节点”为zbreak;// restart if lost race to append to b,多线程情况下,break才可能发生(其它线程对b进行了操作)// 随机获取一个level,然后在“第1层”到“第level层”的链表中都插入新建节点intlevel=randomLevel();if(level>0)insertIndex(z,level);returnnull;}}}
publicVremove(Objectkey){returndoRemove(key,null);}finalVdoRemove(Objectokey,Objectvalue){Comparable<?superK>key=comparable(okey);for(;;){Node<K,V>b=findPredecessor(key);//前置节点Node<K,V>n=b.next;for(;;){if(n==null)returnnull;Node<K,V>f=n.next;if(n!=b.next)// inconsistent readbreak;Objectv=n.value;if(v==null){// n is deletedn.helpDelete(b,f);break;}if(v==n||b.value==null)// b is deletedbreak;intc=key.compareTo(n.key);if(c<0)returnnull;if(c>0){b=n;n=f;continue;}if(value!=null&&!value.equals(v))returnnull;if(!n.casValue(v,null))// 设置b的后继节点为nullbreak;if(!n.appendMarker(f)||!b.casNext(n,f))findNode(key);// Retry via findNodeelse{findPredecessor(key);// Clean indexif(head.right==null)tryReduceLevel();}return(V)v;}}}