1.简介
Elasticsearch 是一个建立在全文搜索引擎 Apache Lucene™ 基础上的分布式的,高可用的,基于json格式的数据构建索引,准实时查询的搜索引擎。Lucene 是当今最先进最高效的全功能开源搜索引擎框架,但是Lucene使用非常复杂。
Elasticsearch使用 Lucene 作为内部引擎,但是在你使用它做全文搜索时,只需要使用统一开发好的API即可,而并不需要了解其背后复杂的 Lucene 的运行原理。
Elasticsearch是一种准实时搜索,其实是可以做到实时的,因为lucene是可以做到实时的,但是这样做,要么是牺牲索引的效率(每次都索引之后刷新),要么就是牺牲查询的效率(每次查询之前都进行刷新),所以 采取一种折中的方案,每隔n秒自动刷新,这样你创建索引之后,最多在ns之内肯定能查到,这就是所谓的准实时(near real-time)查询,缺省是刷新间隔时间是1秒,可以通过index.refresh_interval参数修改间隔.
刷新是为了让文档可以搜索到,但是不保证这些数据被写入disk进入一个永久的存储状态,数据会被先被写入一个事务日志,然后在适当的时候持久化到磁盘中.
官网:https://www.elastic.co/products/elasticsearch
文档:https://www.elastic.co/guide/index.html
github地址:https://github.com/elastic/elasticsearch
博客地址:https://www.elastic.co/blog
其优点很吸引人:
1.分布式,可扩展,高科用(Distributed, scalable, and highly available);
2.提供实时搜索和分析(Real-time search and analytics capabilities);
3.复杂的RESTful API接口(Sophisticated RESTful API);
其特征如下:
1.Real-Time Data
2.Real-Time Analytics
3.Distributed
最开始规模可能很小,elasticsearch很方便的支持横向扩展,通过简单的在集群中增加节点就可以
4.High Availability
Elasticsearch集群是弹性的,它可以自动的感知新增的或者失效的节点,自动做数据的分发和均衡,保证数据客房问并且是安全的.
5.Multitenancy
集群可能包含多个索引(index),它们可以独立的提供查询服务,也可以组合在一起对外提供查询服务.
6.Full-Text Search
支持多种开发语言
7.Document-Oriented
将真实世界的复杂对象结构化乘JSON文档.所有字段默认都建立索引,所有的索引都可以单独提供查询.并且瞬间(breathtaking speed)返回复杂结果.
8.Schema-Free
对一个JSON文档建立索引,就会自动识别数据的结构和类型,创建所有并对外提供搜索服务.同时也可以自定义数据如何建立索引.
9.Developer-Friendly, RESTful API
Elasticsearch是API驱动的.基本所有的操作都可以通过一个简单的使用JSON格式数据的HTTP上的RESTful API.提供了很多种语言的Client.
10.Per-Operation Persistence
Elasticsearch将数据安全放在第一位.任何文档的变更都会记录在集群中多个节点上的事物日志,以此来将数据丢失几率降低到最小.
11.Apache 2 Open Source License
12.Build on top of Apache Lucene
Elasticsearch以Lucene为基础提供其优秀的分布式搜索和分析能力.
13.Conflict Management
2.安装
2.1 elasticsearch安装
安装很简单:
1.下载并解压
下载地址:https://www.elastic.co/downloads/elasticsearch
这里下载是1.5.2版本,解压之后可以创建软链es:
```
xiaobaoqiu@xiaobaoqiu:~/elasticsearch$ ln -s elasticsearch-1.5.2 es
```
目录下主要三个文件夹:
```
xiaobaoqiu@xiaobaoqiu:~/elasticsearch/es$ ll
总用量 48
drwxr-xr-x 5 xiaobaoqiu xiaobaoqiu 4096 4月 27 09:22 ./
drwxr-xr-x 3 xiaobaoqiu xiaobaoqiu 4096 5月 20 14:40 ../
drwxr-xr-x 2 xiaobaoqiu xiaobaoqiu 4096 4月 27 09:22 bin/
drwxr-xr-x 2 xiaobaoqiu xiaobaoqiu 4096 5月 20 14:42 config/
drwxr-xr-x 3 xiaobaoqiu xiaobaoqiu 4096 4月 27 09:22 lib/
-rw-rw-r-- 1 xiaobaoqiu xiaobaoqiu 11358 4月 27 07:05 LICENSE.txt
-rw-rw-r-- 1 xiaobaoqiu xiaobaoqiu 150 4月 27 07:05 NOTICE.txt
-rw-rw-r-- 1 xiaobaoqiu xiaobaoqiu 8499 4月 27 09:03 README.textile
```
其中bin包含一些启动脚本(包括windows下的bat脚本和linux下的shell脚本),config主要是配置文件,lib包括es依赖的jar,在里面就可以看到熟悉的Lucene,查询,高亮等依赖的jar包.
启动elasticsearch之后会产生log目录,用于记录elasticsearch系统的一些中心日志信息:
```
-rw-r--r-- 1 0 5月 20 15:05 elasticsearch_index_indexing_slowlog.log
-rw-r--r-- 1 0 5月 20 15:05 elasticsearch_index_search_slowlog.log
-rw-r--r-- 1 1254 5月 20 15:06 elasticsearch.log
```
其中elasticsearch.log是系统日志,记录什么类型的日志,日志的命名及日志文件的滚动(Rolling)策略等由config目录下的logging.yml配置文件决定.
启动elasticsearch之后会产生data目录,用于
elasticSearch的数据存放位置
2.启动
直接启动bin目录下的elasticsearch的shell:
```
xiaobaoqiu@xiaobaoqiu:~/elasticsearch/es/bin$ ./elasticsearch -d
```
3.验证
直接本机浏览器访问:http://localhost:9200/
```
{
status: 200,
name: "Agon",
cluster_name: "elasticsearch",
version: {
number: "1.5.2",
build_hash: "62ff9868b4c8a0c45860bebb259e21980778ab1c",
build_timestamp: "2015-04-27T09:21:06Z",
build_snapshot: false,
lucene_version: "4.10.4"
},
tagline: "You Know, for Search"
}
```
这说明Elasticsearch集群已经上线运行了,这时我们就可以进行各种实验了.
2.2 集群管理工具插件
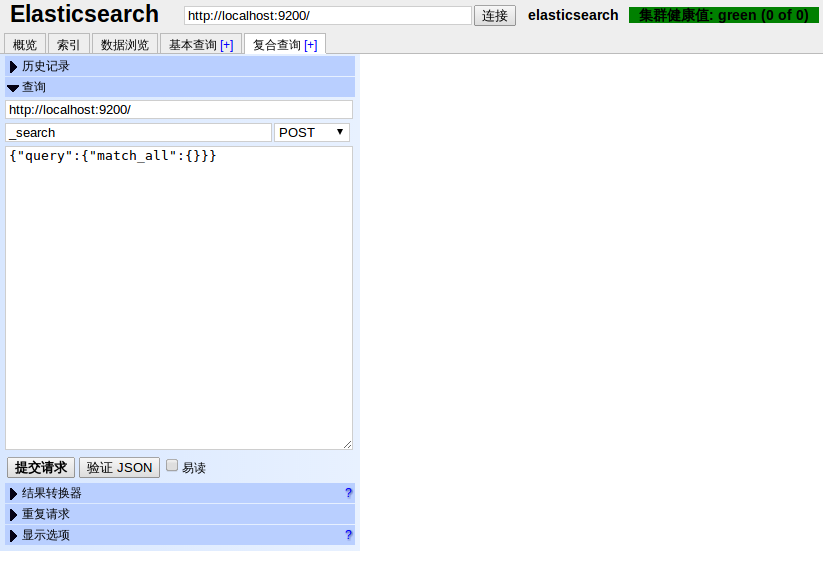
elasticsearch-head是一个elasticsearch的集群管理工具,它是完全由html5编写的独立网页程序,其他它可以更好的获得各个切片和节点的信息.
该工具的git地址是: https://github.com/Aconex/elasticsearch-head
安装该插件:
1 2 3 | |
然后就可以访问(可以使用具体节点的IP): http://localhost:9200/_plugin/head/
图形化界面如下,包括集群的健康状况等信息:
2.3 集群监控工具插件
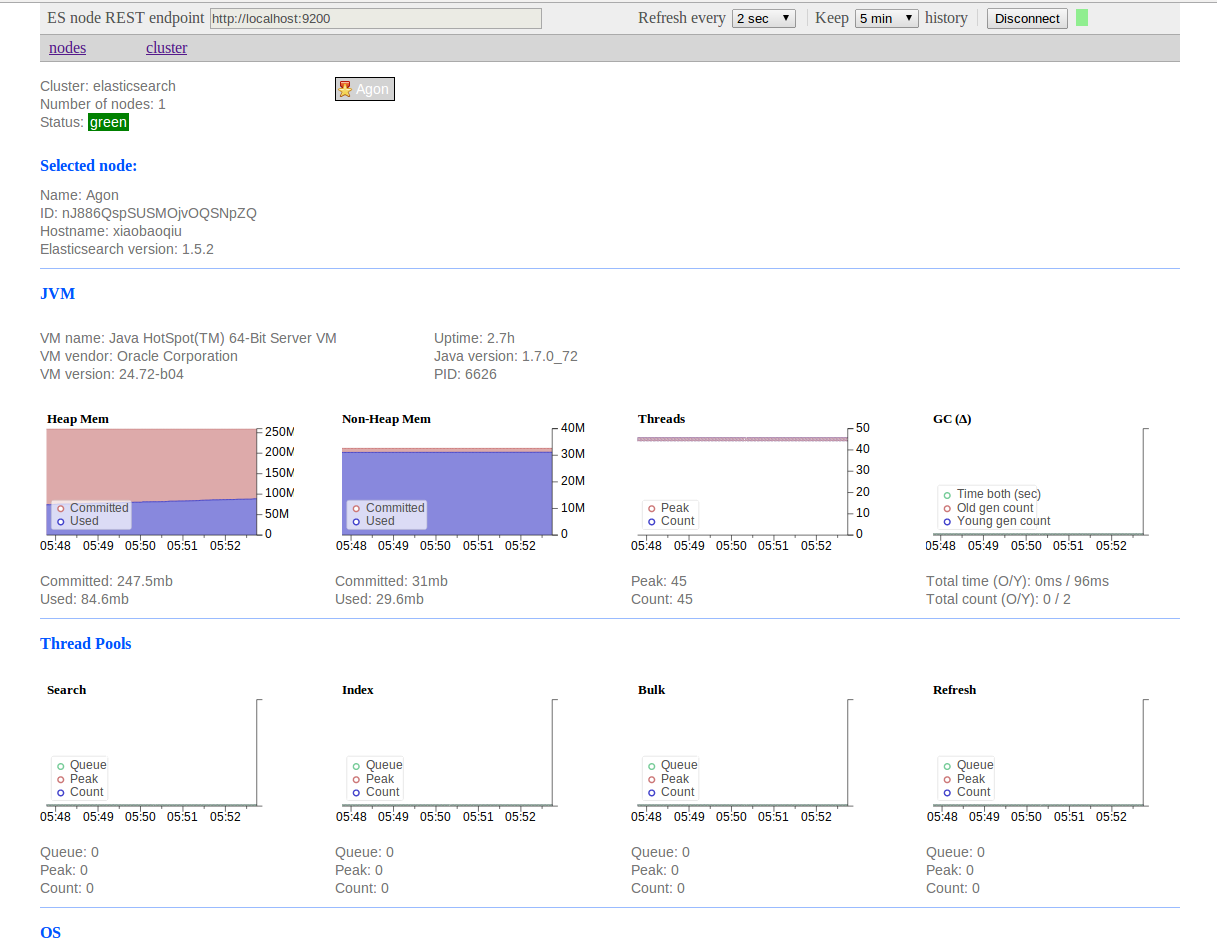
bigdesk是elasticsearch的一个集群监控工具,可以通过它来查看es集群的各种状态,如:cpu、内存使用情况,索引数据、搜索情况,http连接数等。
项目git地址: https://github.com/lukas-vlcek/bigdesk
安装该插件:
1 2 3 | |
然后就可以访问(可以使用具体节点的IP): http://localhost:9200/_plugin/bigdesk/
图形化界面如下,包括JVM,Thread Pools,OS,Process,HTTP & Transport,Indices和File system等监控图:
2.4 安装Marvel
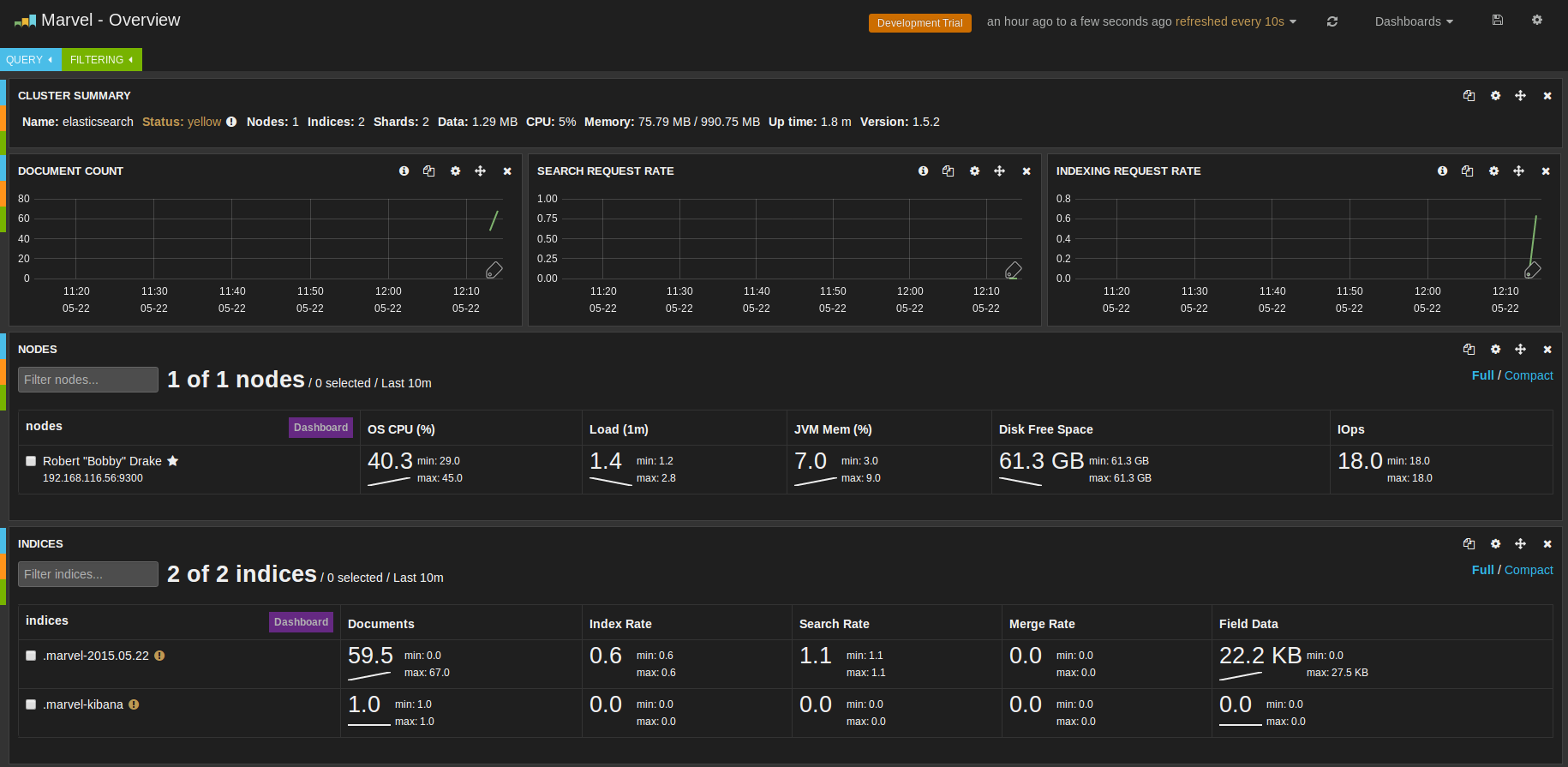
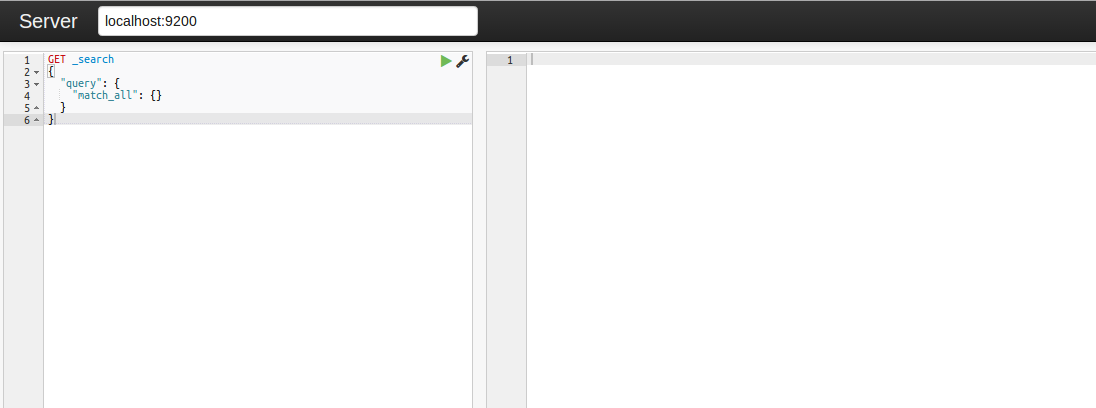
Marvel是Elasticsearch的管理和监控工具,是一个商业版本的插件,在开发环境下免费使用。它包含了一个叫做Sense的交互式控制台,使用户方便的通过浏览器直接与Elasticsearch进行交互。
运行以下命令来下载和安装Marvel:
1 2 3 | |
Marvel包括一系列酷炫的监控,还有一个Sense的交互式控制台:
你可能想要禁用监控,你可以通过以下命令关闭Marvel:
1
| |
3.基本概念
3.1 集群和节点
节点是Elasticsearch运行的实例。集群是一组有着同样cluster.name的节点,它们协同工作,互相分享数据,提供了故障转移和扩展的功能。当然一个节点也可以是一个集群。ES集群有自动发现的机制,只要几个节点用的是一个clustername,并且在一个局域网内,那么这些节点就可以自动的发现对方,并组成一个集群.
我们上面的运行就是一个单节点的集群.节点的cluster.name在配置文件elasticsearch.yml中配置,默认就叫elasticsearch:
1
| |
ES的集群是一个去中心化的集群,每一个节点都可以被选举为主节点,如果主节点挂了,集群就会选举出新的主节点。
主节点的作用主要是管理集群,例如感知集群节点的增加和减少,平衡数据分配等.
ES集群对外是透明的,各个节点之间协同工作,分享数据,我们不管访问的是哪一个节点,这个节点都知道数据存在于哪个节点上,然后转发请求到数据所在的节点上,并且负责收集各节点返回的数据,最后一起返回给客户端.
3.2 分片(shard)
一个索引会被分割为多个片段存储,这样可以充分使用节点的吞吐率
3.2 索引(index)
相当于数据库
3.3 类型(type)
相当于数据库中的表
3.4 文档(doc)
相当于数据库中的一条记录,json串
3.5 字段(Field)
相当路数据库中的列。