1.Protocol Buffers简介
最近项目中接触到久闻大名的Protocol Buffers。简单学习Protocol Buffers是什么,能做什么,为什么需要它,怎么使用它。
Protocol Buffers官网:https://developers.google.com/protocol-buffers/
Protocol Buffers官网(中文):https://developers.google.com/protocol-buffers/?hl=zh-CN
Git地址:https://github.com/google/protobuf
Java API:https://developers.google.com/protocol-buffers/docs/reference/java/?hl=zh-CN
proro文件的编写指南:https://developers.google.com/protocol-buffers/docs/style?hl=zh-CN
Java使用指南:https://developers.google.com/protocol-buffers/docs/javatutorial?hl=zh-CN
protocol buffers是google提供的一种将结构化数据进行序列化和反序列化的方法,其优点是语言中立,平台中立,可扩展性好,目前在google内部大量用于数据存储,通讯协议等方面。语言中立说明和语言无关,可以作为跨语言的通信协议。平台中立说明Protocol Buffers可以作为不同平台之间的通信协议;可扩展性好可以理解为protocol buffers支持嵌套。
PB在功能上类似XML,但是序列化后的数据更小,解析更快,使用上更简单。用户只要按照proto语法在.proto文件中定义好数据的结构,就可以使用PB提供的工具(protoc)自动生成处理数据的代码,使用这些代码就能在程序中方便的通过各种数据流读写数据。
PB目前支持Java, C++和Python3种语言(截止目前已经额外支持C#,Ruby和Object-C)。另外,PB还提供了很好的向后兼容,即旧版本的程序可以正常处理新版本的数据,新版本的程序也能正常处理旧版本的数据。
2.Protocol Buffers安装
1.下载源码 从https://github.com/google/protobuf%E4%B8%8B%E8%BD%BD%E6%BA%90%E7%A0%81
2.根据README安装 (1).使用./autogen.sh生成configure脚本; (2).配置./configure,默认在/usr/local下,可以指定路径 (3).make (4).make check (5).make install
这里安装的是最新的Protoc 3。安装之后,就会有一个根据Message文件产生对应代码文件的工具protoc:
1 2 | |
在帮助文当中就可以看到如何生成各种类型的文件的方式:
1 2 3 4 5 6 7 | |
3.Protocol Buffers Demo in Java
参考官网的一个例子,message是定义protobuf的关键词,Person表示一个人的信息,包括id,name,email和phone四个信息,其中name和id是必须的,email是可选的,phone是数组形式并且phone本身也是一种消息(message),PhoneNumber内部包含了枚举类型PhoneType,主要枚举的定义和Java有点不同,这里是分号分割的。1234这种序号表示字段在数据中的顺序,新增字段依次增加这个序号就行。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | |
string和int32是protobuf支持的基本类型,所有支持的类型及其含义如下:
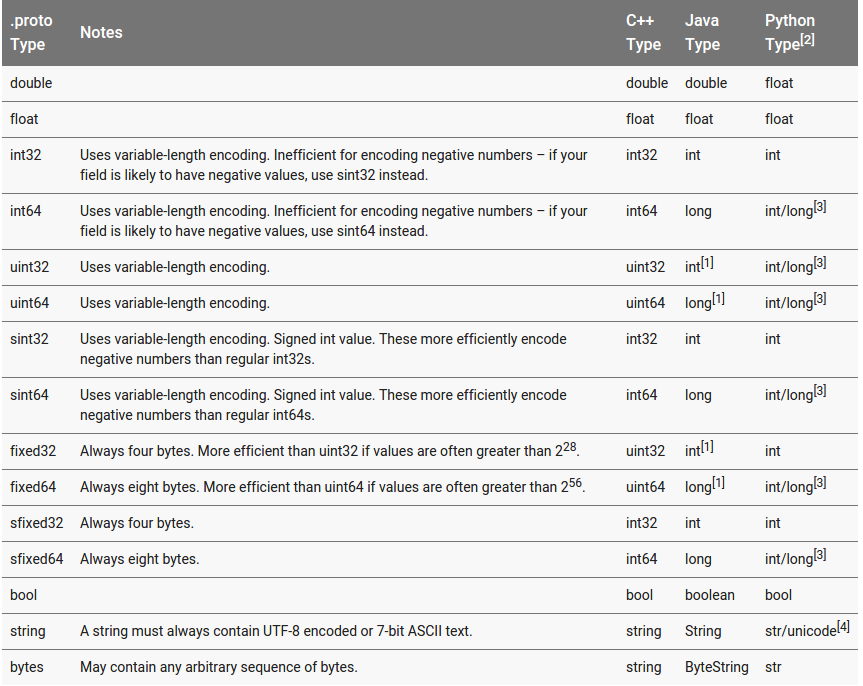
如下生成message对应的Java文件如下:
1
| |
生产数据方直接使用对应的Builder生成对象,然后往流里面写数据:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | |
消费数据方可以直接从流中读取并解析对象:
1 2 3 4 5 6 7 8 | |
4.自描述消息
5.序列化性能
参考git上的各种序列化的测试结果: https://github.com/eishay/jvm-serializers/wiki