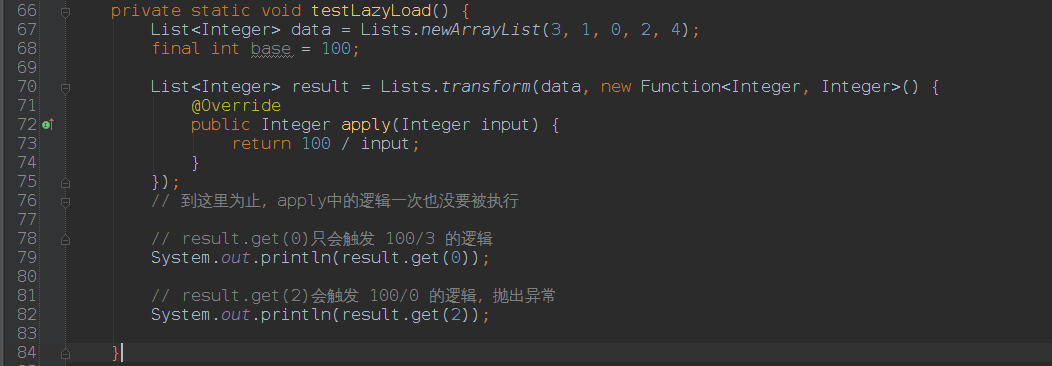
编译器还生成了一个静态初始话器,就是字节码中static{};这一行下面的代码,其中的字节码创建了两个FruitEnum对象,同时分别赋值给APPLE和ORANGE这两个属性,调用的构造函数是定义在java.lang.Enum中的protected Enum(String name, int ordinal)方法。
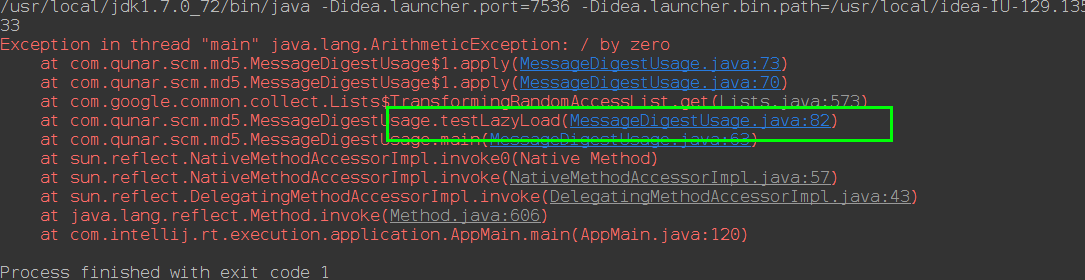
publicstatic<F,T>List<T>transform(List<F>fromList,Function<?superF,?extendsT>function){return(fromListinstanceofRandomAccess)?newTransformingRandomAccessList<F,T>(fromList,function):newTransformingSequentialList<F,T>(fromList,function);}privatestaticclassTransformingSequentialList<F,T>extendsAbstractSequentialList<T>implementsSerializable{finalList<F>fromList;finalFunction<?superF,?extendsT>function;TransformingSequentialList(List<F>fromList,Function<?superF,?extendsT>function){this.fromList=checkNotNull(fromList);this.function=checkNotNull(function);}/** * The default implementation inherited is based on iteration and removal of * each element which can be overkill. That's why we forward this call * directly to the backing list. */@Overridepublicvoidclear(){fromList.clear();}@Overridepublicintsize(){returnfromList.size();}@OverridepublicListIterator<T>listIterator(finalintindex){returnnewTransformedListIterator<F,T>(fromList.listIterator(index)){@OverrideTtransform(Ffrom){returnfunction.apply(from);}};}privatestaticfinallongserialVersionUID=0;}//AbstractSequentialList.javapublicEget(intindex){try{returnlistIterator(index).next();}catch(NoSuchElementExceptionexc){thrownewIndexOutOfBoundsException("Index: "+index);}}
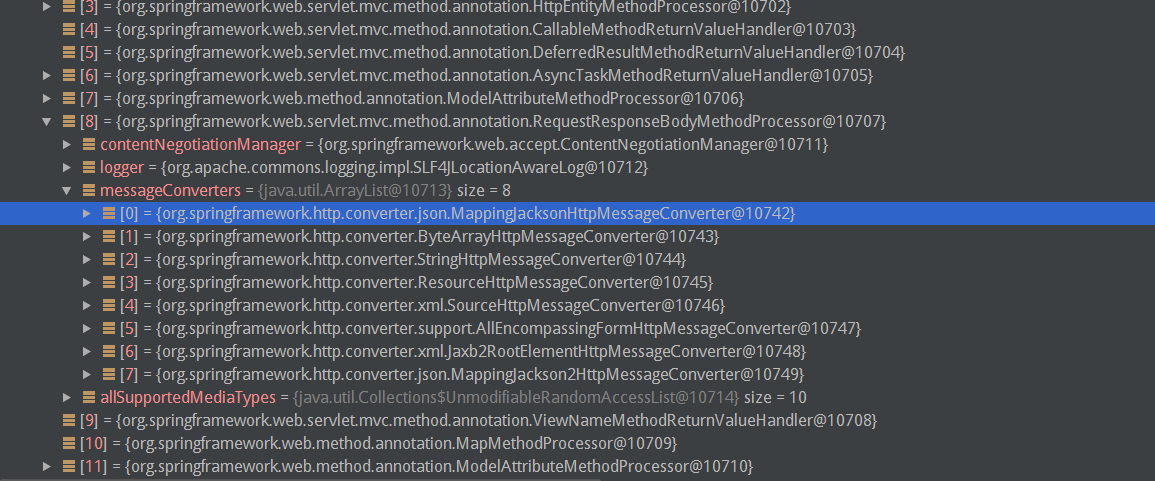
@OverrideprotectedvoidwriteInternal(Objectobject,HttpOutputMessageoutputMessage)throwsIOException,HttpMessageNotWritableException{JsonEncodingencoding=getJsonEncoding(outputMessage.getHeaders().getContentType());JsonGeneratorjsonGenerator=this.objectMapper.getJsonFactory().createJsonGenerator(outputMessage.getBody(),encoding);// A workaround for JsonGenerators not applying serialization features// https://github.com/FasterXML/jackson-databind/issues/12if(this.objectMapper.getSerializationConfig().isEnabled(SerializationConfig.Feature.INDENT_OUTPUT)){jsonGenerator.useDefaultPrettyPrinter();}try{if(this.prefixJson){jsonGenerator.writeRaw("{} && ");}this.objectMapper.writeValue(jsonGenerator,object);//序列化逻辑}catch(JsonProcessingExceptionex){thrownewHttpMessageNotWritableException("Could not write JSON: "+ex.getMessage(),ex);}}