今天项目发布的出现一个异常:
1
| |
一看到这个51.0,直觉想起了JDK 1.7。追查问题发现是新定义了maven-compiler-plugin,并且指定了版本为1.7,但是线上应用机器上的JDK版本是1.6,导致编译产生的1.7版本的class文件在1.6(version为50)上无法执行。
maven-compiler-plugin用来指定编译时候的JDK版本
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | |
今天项目发布的出现一个异常:
1
| |
一看到这个51.0,直觉想起了JDK 1.7。追查问题发现是新定义了maven-compiler-plugin,并且指定了版本为1.7,但是线上应用机器上的JDK版本是1.6,导致编译产生的1.7版本的class文件在1.6(version为50)上无法执行。
maven-compiler-plugin用来指定编译时候的JDK版本
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | |
MYSQL 5.5 之前, UTF8 编码只支持1-3个字节,只支持BMP这部分的unicode编码区, BMP是从哪到哪,到 http://en.wikipedia.org/wiki/Mapping_of_Unicode_characters 这里看,基本就是0000~FFFF这一区。 从MYSQL5.5开始,可支持4个字节UTF编码utf8mb4,一个字符最多能有4字节,所以能支持更多的字符集。
utf8mb4兼容utf8,且比utf8能表示更多的字符。
在做移动应用时,会遇到ios用户会在文本的区域输入emoji表情,emoji就是表情符号,在手机短信里面已经是很流行使用的一种表情。
因为utf8mb4是utf8的超集,理论上即使client修改字符集为utf8mb4,也会不会对已有的utf8编码读取产生任何问题。
1.MySQL在处理utf8mb4数据时,要比utf8慢;
2.存储字符数量,utf8mb4要比utf8少;
3.TIMESTAMP NOT NULL DEFAULT 类型的字段,当我们在程序中传入NULL时,Mysql 5.5会自动填充默认值,而5.6不会自动填充,这就违反了非空约束,会报错;
4.在mysql 5.6版本, utf8的表和utf8mb4的表join查询会导致索引失效;
这里想总结一下使用Mysql的一些架构,注意不是Mysql源码的架构。
数据量不大,业务简单的情况下,直接单点的mysql instance足够。
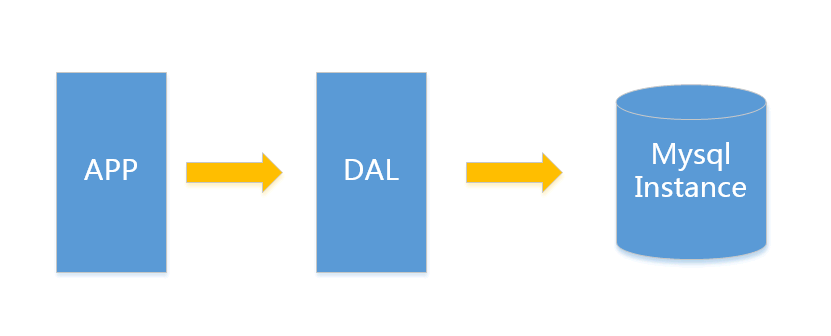
1.简单,不存在数据一致性等问题;
1.单机存储数据量有限;
2.数据索引单机内存可能放不下,导致和只能加载部分索引,印象性能;
3.单机访问速度有极限;
4.读写混合,不正当的写操作导致的锁表等问题,可能导致读操作也失败,进而拖死整个系统;
5.无法容灾;
很多业务场景简单的,单表可以一般足够,比如对于用户信息这类表 (3个索引),16G内存能放下大概2000W行数据的索引,简单的读和写混合访问量3000/s左右没有问题。
当单表遇到瓶颈的时候,最简单的想法是垂直拆分,从业务角度来看,将关联性不强的数据拆分到不同的instance上,从而达到消除瓶颈的目标。
另外,绝大部分的业务常见读写复合2-8原则,即80%的数据库操作会是读操作,因此对于重复读类型比较多的场景,我们还可以加一层cache,来减少对DB的压力。
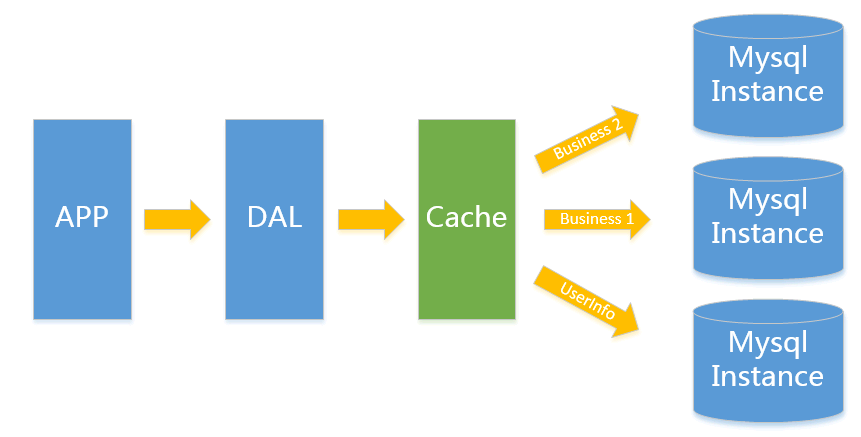
1.业务隔离,互不影响;
1.读写混合的问题依然存在;
基于业务的读写2-8原则,我们将读写分离,即读和写打到不同的数据库服务器,通常读服务器会有多台,这即典型的Master-Slave结构,主库(Master)抗写压力,通过从库(Slave)来分担读压力。MS结构非常适合读多写少的应用场景,比如博客类网站等。
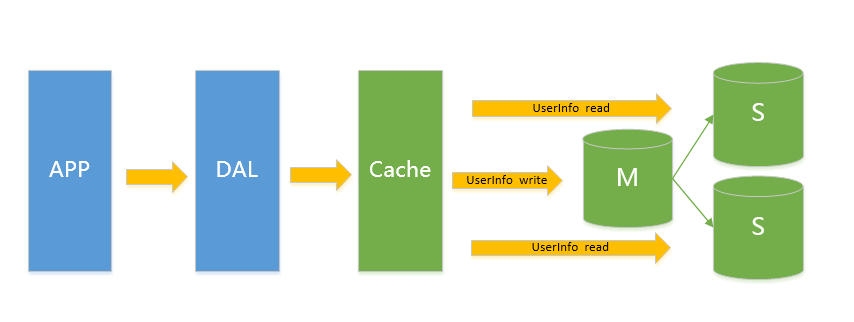
Slave通过binlog来同步Master的数据变更:
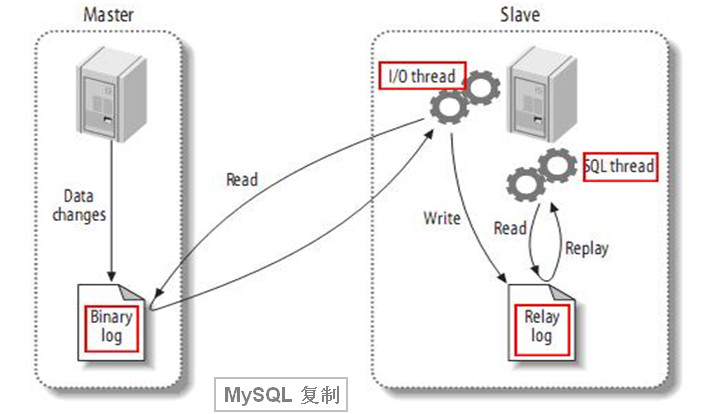
主从机器的硬件配置和MySQL版本、各种参数配置最好都要一样,这样才能保证出问题时应用程 序能够平滑地从主库切换到备库上。
1.读写分离,减少相互影响;
2.实时备份;
1.数据一致性难以保障;
2.主从切换麻烦,而且切换所带来的麻烦会随着备库的增多而逐步上升;
在Application和DB中间加以层Proxy,Proxy来解析sql协议,按sharding key 来寻找cluster, 判断是读操作还是写操作来请求主服务器或者从服务器,这一切内部的细节都由proxy来屏蔽。
Proxy做的工作包括:
1.SQL解析
2.SQL改写
3.查询Dispatch
4.读写分离、主从切换逻辑
5.缓冲区控制
6.归并+排序
heartbeat可以资源(VIP地址及程序服务)从一台有故障的服务器快速的转移到另一台正常的服务器提供服务,heartbeat和keepalived相似,heartbeat可以实现failover功能,但不能实现对后端的健康检查。
http://linux-ha.org/wiki/Main_Page
DRBD(Distributed Replicated Block Device)是一个基于块设备级别在远程服务器直接同步和镜像数据的软件,用软件实现的、无共享的、服务器之间镜像块设备内容的存储复制解决方案。
它可以实现在网络中两台服务器之间基于块设备级别的实时镜像或同步复制(两台服务器都写入成功)/异步复制(本地服务器写入成功),相当于网络的RAID1,由于是基于块设备(磁盘,LVM逻辑卷),在文件系统的底层,所以数据复制要比cp命令更快。DRBD已经被MySQL官方写入文档手册作为推荐的高可用的方案之一。
官方站点:http://www.drbd.org/
适用于数据库访问量不太大,短期内访问量增长不会太快,对数据库可用性要求非常高的场景。
主从切换是Master-Slave结构的一个硬伤,如果备库只是用来实时备份数据和承担小部分读压力,那么MM结构将会是取代MS结构的不二之选。MM(Master-Master)就是主主结构,任意一个时刻,只有一个实际意义上的Master,另外一个作为Slave,只有当前的Master出现故障或者问题的使用,两台Master的角色切换,即原始的Master变为Slave,而原始的Slave切换为Master。
MMM(Master-Master replication manager for MySQ)是一套支持双主故障切换和双主日常管理的脚本程序。MMM使用Perl语言开发,主要用来监控和管理MySQL Master-Master复制。
MMM项目来自 Google:http://code.google.com/p/mysql-master-master
官方网站为:http://mysql-mmm.org
虽然叫做双主复制,但是业务上同一时刻只允许对一个主进行写入,另一台备选主上提供部分读服务,以加速在主主切换时刻备选主的预热,可以说MMM这套脚本程序一方面实现了故障切换的功能,另一方面其内部附加的工具脚本也可以实现多个slave的read负载均衡。
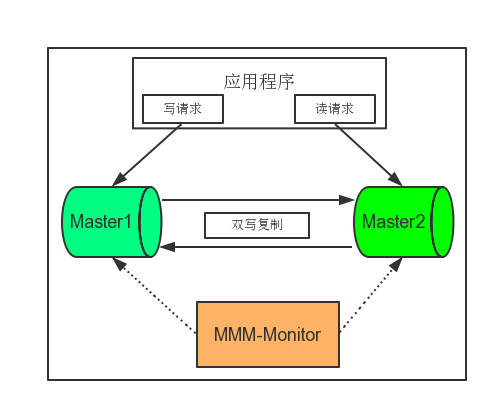
典型的MM结构,即只有两台数据库Master服务器:
MM+Slaves结构,即两台数据库Master服务器加多台Slave服务器:
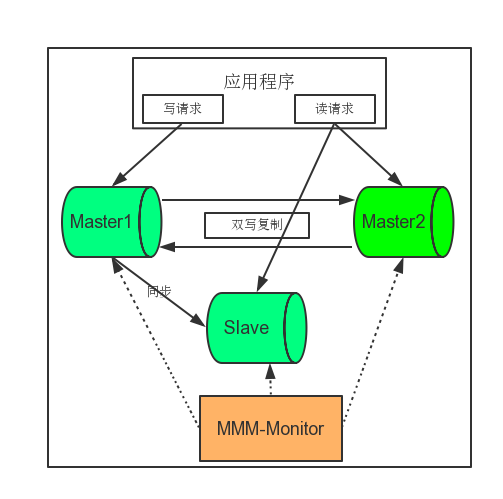
MMM主要的功能通过下面三个脚本来实现:
mmm_mond: 负责所有的监控工作的监控守护进程,决定节点的活动;
mmm_agentd:运行在mysql服务器上的代理守护进程,通过远程服务提供给监控节点;
mmm_control:通过命令行管理mmm_mond进程;
mysql-mmm的监管端会提供多个虚拟IP(VIP),包括一个可写VIP,多个可读VIP,通过监管端每十秒种(默认间隔)轮询一次MySQL节点来检查其状态,仅其中的一台服务器接收到写入器角色(写的VIP,Master的某一个),其他的可以拥有阅读器角色(读VIP,包括一个备份的Master),当写库不可用(比如宕机等),MMM会自动将写VIP给另外一台Master。
Mysql需要创建一个mmm_monitor和多个mmm_agent账户并授权。
1.克服了MS结构主从切换困难的问题;
2.是一种HA(高可用)架构(Easy Failover)
1.MMM不适用于对数据一致性要求很高的环境,某种情况下存在双写的问题
其他问题参考:
1.[What's wrong with MMM?](http://www.xaprb.com/blog/2011/05/04/whats-wrong-with-mmm/)
2.[Problems with MMM for MySQL](http://code.openark.org/blog/mysql/problems-with-mmm-for-mysql)
最近我们系统遇到过一次MMM导致的问题:
1.在当前的主Master(称之为Master-A)上有读写请求,从T1时刻开始,由于大量的慢查询,且这台机器善有多个Mysql Instance,导致在业务高峰期,当前的主Master对Monitor(Master-A)没有响应,因此Monitor认为这个Master(Master-A)宕机了,因此在T2时刻将读和写的VIP都漂移到另外一台备份Master(Master-B)上,这种情况下,Master-A和Master-B之间的双写复制中断,但是实际上Master-A上的写操作还在进行,即在T2之后的一段时间内,Master-A和Master-B上都存在写操作,并且不存在双写复制,当Master-A机器恢复,读VIP漂移到Master-A上,开始执行双写复制,发现存在冲突,因此双写导致数据存在冲突(比如自增ID)。
http://www.infoq.com/cn/news/2013/03/MySQL-Reference-Architectures http://www.admin10000.com/document/4539.html http://www.open-open.com/lib/view/open1341302877043.html http://mysql-mmm.org/mysql-mmm.html http://www.cnblogs.com/gomysql/p/3671896.html http://www.luocs.com/archives/849.http html://wiki.corp.qunar.com/download/attachments/63242976/%E5%91%A8%E5%BD%A6%E4%BC%9F%E3%80%8AMySQL%E9%AB%98%E5%8F%AF%E7%94%A8%E6%9E%B6%E6%9E%84%E6%BC%94%E5%8F%98%E4%B9%8B%E8%B7%AF_%E4%BB%8EMMM%E5%88%B0PXC%E3%80%8B.pdf?version=1&modificationDate=1418272276416
学习一下虚拟IP和IP漂移的概念。
在 TCP/IP 的架构下,所有想上网的电脑,不论是用何种方式连上网路,都必须要有一个唯一的 IP-address。事实上IP地址是主机硬件地址的一种抽象,简单的说,MAC地址是物理地址,IP地址是逻辑地址。
虚拟IP,就是一个未分配给真实主机的IP,也就是说对外提供服务器的主机除了有一个真实IP外还有一个虚IP,使用这两个IP中的任意一个都可以连接到这台主机。
虚拟IP一般用作达到HA(High Availability)的目的,比如让所有项目中数据库链接一项配置的都是这个虚IP,当主服务器发生故障无法对外提供服务时,动态将这个虚IP切换到备用服务器。
ARP是地址解析协议,它的作用很简单,将一个IP地址转换为MAC地址,然后给传输层使用。
每台主机中都有一个ARP高速缓存,存储同一个网络内的IP地址与MAC地址的对应关 系,以太网中的主机发送数据时会先从这个缓存中查询目标IP对应的MAC地址,会向这个MAC地址发送数据。操作系统会自动维护这个缓存。
在Linux下可以使用arp命令操作ARP高速缓存。
比如存在物理机A(IP是192.168.192.54 )和物理机器B(IP是192.168.192.40),A作为对外服务的主服务器(比如数据库主库),B作为备份机器,两台服务器之间的通信是通过Heartbeat,即主服务器会定时的给备份服务器发送数据包,告知主服务器服务正常,当备份服务器在规定时间内没有收到主服务器的Heartbeat,就会认为主服务器宕机,则备份服务器就会升级为主服务器。假设物理机A的ARP缓存如下:
1 2 3 4 5 | |
另外物理机器B(IP是192.168.192.40)的ARP缓存如下:
1 2 3 4 5 | |
当机器B通过BeatHeart得知机器A对外服务质量低于预期的时候(比如发生故障,服务无响应),会将自己的ARP缓存发送出去,让路由器修改路由表,告知虚拟地址应该指向我(物理机器B,192.168.192.40),这时候,外界再次访问虚拟IP的时候,机器B会变成主服务器,而A降级为备份服务器。这就完成了主从机器的自动切换,这一切对外界是透明的。
上面的VIP自动切换的过程就称之为IP漂移。
我们可以通过Keepalived来实现这个过程。 Keepalived是一个基于VRRP协议(Virtual Router Redundancy Protocol,即虚拟路由冗余协议)来实现的LVS(负载均衡器)服务高可用方案,可以利用其来避免单点故障。一个LVS服务会有2台服务器运行Keepalived,一台为主服务器(MASTER),一台为备份服务器(BACKUP),但是对外表现为一个虚拟IP,主服务器会发送特定的消息给备份服务器,当备份服务器收不到这个消息的时候,即主服务器宕机的时候, 备份服务器就会接管虚拟IP,继续提供服务,从而保证了高可用性。
今天出现一次dubbo的Thread pool exhausted导致服务不可用。根本原因是Mysql的慢查询。
1
| |
RejectedExecutionException表示线程池已经达到最大值,并且没有空闲连,拒绝执行了一些任务。 Thread pool exhausted通常是min和max不一样大时,表示当前已创建的连接用完,进行了一次扩充,创建了新线程,但不影响运行。
原因可能是连接池不够用,可以在provider的配置文件中设置threads参数:
1
| |
如果线程池已经有200,还不够,通常是业务处理占用线程时间过长, 需优化业务,可通过jstack查看进程的状态,分析当前大多数线程都在干什么,从而分析出哪个地方是瓶颈, 比如,如果大部分线程都在处理SQL,可能是数据库连接不够,或数据源配置错误,或SQL没走索引等。