本文主要想理清同步,异步,阻塞,非阻塞这几个概念;之后理解unix上的五种IO模型。
1.同步VS异步,阻塞VS非阻塞
1.1 同步VS异步
访问数据的方式,同步需要主动读写数据,在读写数据的过程中还是会阻塞;异步只需要I/O操作完成的通知,并不主动读写数据,由操作系统内核完成数据的读写。
同步(synchronous)和异步(asynchronous)是针对应用程序和内核的交互而言的:
(1).同步指的是用户进程触发I/O操作并等待或者轮询的去查看I/O操作是否就绪;
(2).异步是指用户进程触发I/O操作以后便开始做自己的事情,而当I/O操作已经完成的时候会得到I/O完成的通知;
1.2 阻塞VS非阻塞
阻塞(blocking)和非阻塞(non-blocking)是针对于进程在访问数据的时候,根据I/O操作的就绪状态来采取的不同方式,说白了是一种读取或者写入操作函数的实现方式:
(1).阻塞方式下读取或者写入函数将一直等待;
(2).非阻塞方式下,读取或者写入函数会立即返回一个状态值;
2.IO模型
《Unix网络编程卷》将unix上的IO模型分为5类:
(1).Blocking I/O
(2).Nonblocking I/O
(3).I/O Multiplexing (select and poll)
(4).Signal Driven I/O (SIGIO)
(5).Asynchronous I/O (the POSIX aio_functions).
一个读操作通常包括两个不同阶段:
(1).等待数据准备好;
(2).从内核向进程复制数据;
我们以一个从网络读数据为例,当网络数据包到达的时候,首先内核通过网卡读输入数据,数据被复制到内核的缓冲区;然后应用程序从内核中将数据拷贝到应用程序缓冲区。
以从网络读数据为例解释上面提到的5个IO模型, 即应用程序通过socket的recvfrom方法读取网络数据,关于recvfrom方法参考:http://baike.baidu.com/view/1744189.htm.
2.1 Blocking I/O
阻塞IO:应用程序调用recvfrom试图读取数据,其实是通过系统调用从网卡读取网络数据,当网络无数据可读的时候,应用程序会一直等待;当内核从网卡读取完数据,会将数据从内核缓冲区拷贝到应用程序缓冲区,当拷贝完成,应用程序调用recvfrom才算完成。示意图如下:
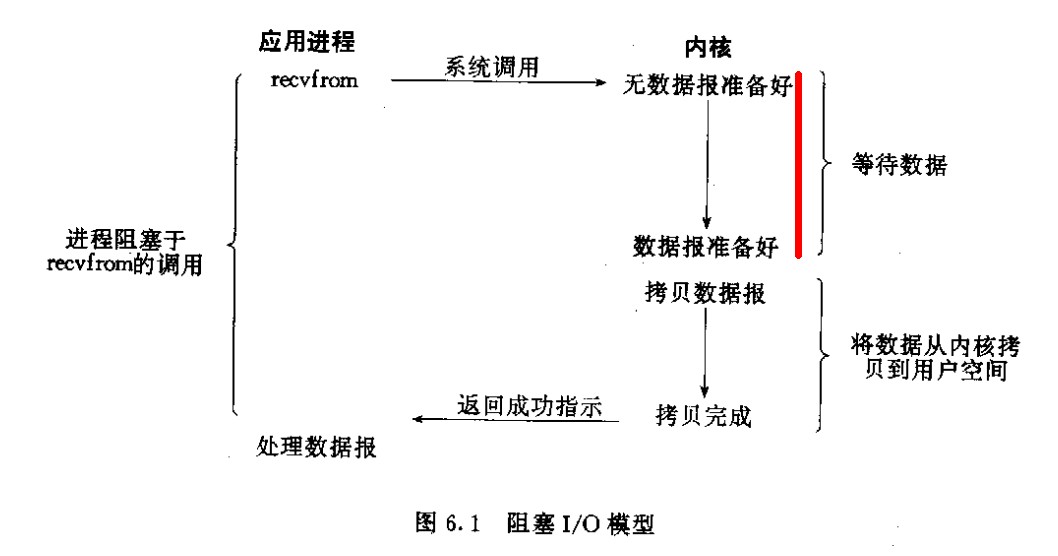
优势在于非常简单,等待的过程中占用的系统资源微乎其微,程序调用返回时,必定可以拿到数据;
但简单也带来一些缺点,程序在数据到来并准备好以前,不能进行其他操作;
2.2 Nonblocking I/O
非阻塞IO:应用程序调用recvfrom试图读取数据,当网络无数据可读的时候,应用程序不是一直等待,而是直接返回错误,过一段时间再去查看数据是否可读,即有一个操作时轮询(polling)。 示意图如下:
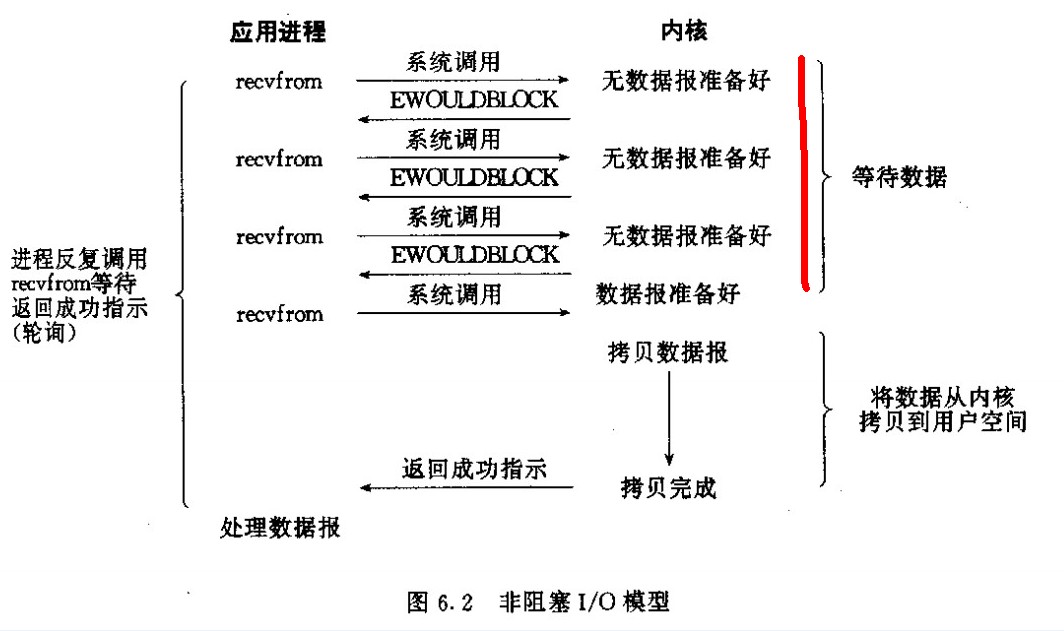
这种模式在没有数据可以接收时,可以进行其他的一些操作;实际应用中,这种I/O模型的直接使用并不常见,因为它需要不停的查询,而这些查询大部分会是无必要的调用,白白浪费了系统资源;非阻塞I/O应该算是一个铺垫,为I/O复用和信号驱动奠定了非阻塞使用的基础。
2.3 I/O Multiplexing
首先I/O多路复用的函数也是阻塞的,但是其与以上两种还是有不同的,I/O多路复用是阻塞在select,epoll这样的系统调用之上,而没有阻塞在真正的I/O系统调用如recvfrom之上。
IO复用的目的:将等待数据准备和将数据拷贝给应用这两个阶段分开处理,让一个线程(而且是内核级别的线程)来处理所有的等待,一旦有相应的IO事件发生就通知继续完成IO操作,虽然仍然有阻塞和等待,但是等待总是发生在一个线程,这时使用多线程可以保证其他线程一旦唤醒就是处理数据。
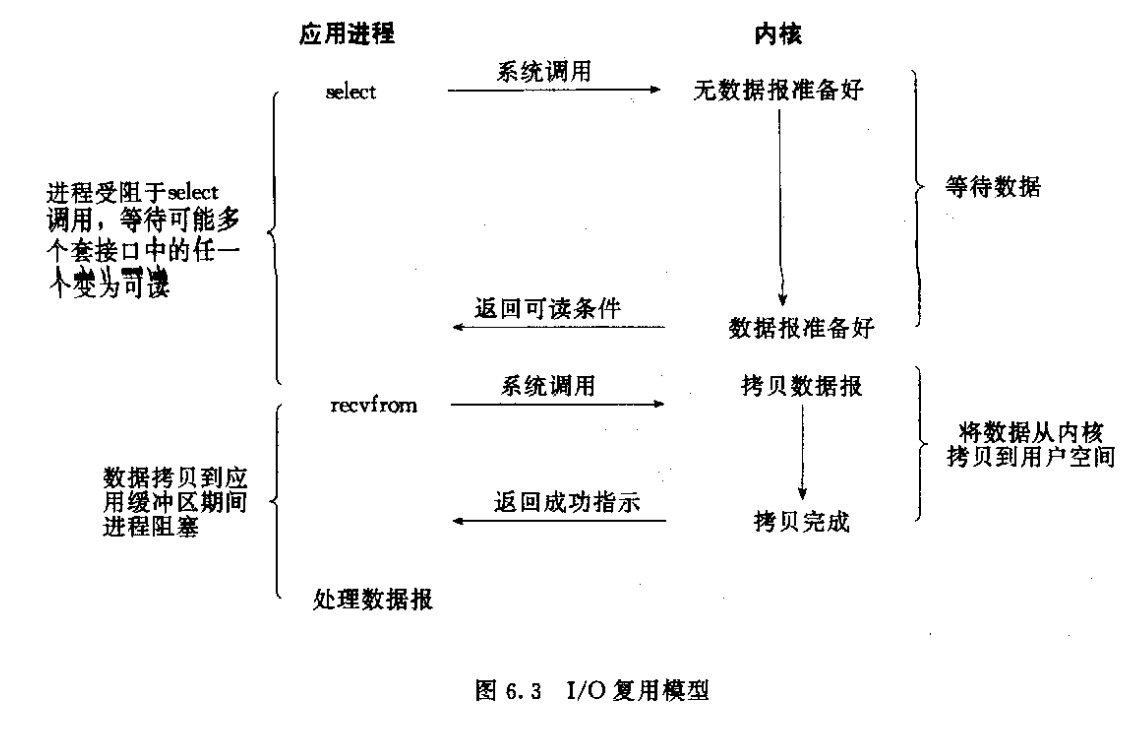
至于select、poll和epoll的区别,推荐这篇文章: http://www.cnblogs.com/Anker/p/3265058.html 。简单来说:select,poll无脑的轮询,忽略了高并发下,轮询本身成了瓶颈,而epoll使用回调实现了轮询真正需要处理的连接。
2.4 Signal Driven I/O
应用线程调用recvfrom试图读取数据,并且直接返回,不管是否有数据可读,内核线程读完数据,给发信号通知应用线程,应用线程收到信息,等待内核线程将数据拷贝给应用线程。
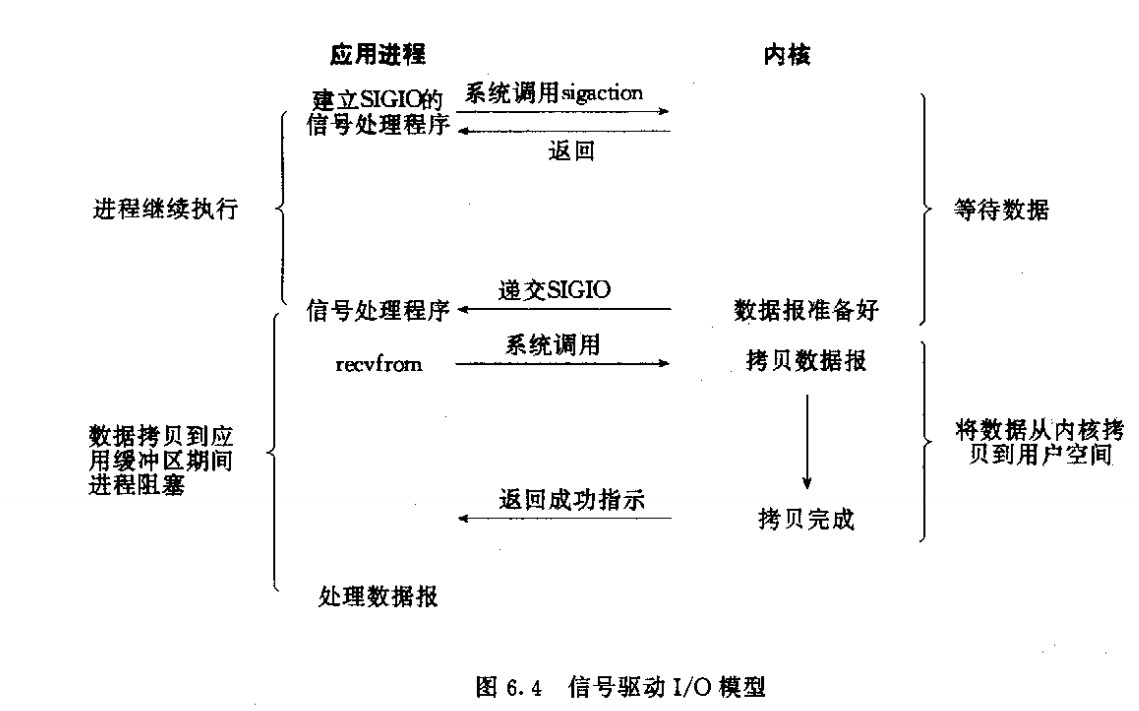
2.5 Asynchronous I/O
这类函数的工作机制是告知内核启动某个操作,并让内核在整个操作(包括将数据从内核拷贝到用户空间)完成后通知我们。
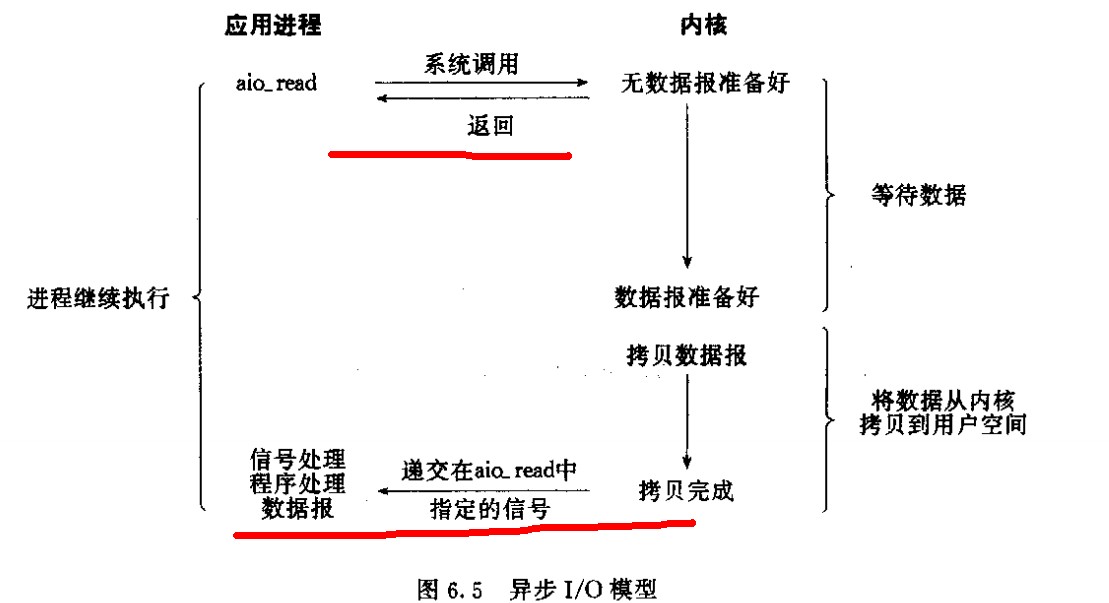
注意,之前的几个模型的recvfrom都是在数据拷贝完成(即第二阶段完成)才返回,而异步IO是在第一阶段直接返回并继续往下执行,数据拷贝完成后系统内核再通知应用进程。
2.6 总结
前4种都是同步IO,只有最后一种是异步IO。他们第二阶段(拷贝数据阶段)是相同的,区别在于第一阶段,同步IO第二阶段是阻塞的,即一定会阻塞于等待数据拷贝完成,而异步IO是不阻塞于数据拷贝,数据拷贝完成,内核进程会通知应用进程。
这就是同步和异步的区别:异步在整个过程都没有阻塞,而同步至少有一个步骤被阻塞(等待内核IO或者等待内核将数据拷贝给应用)。
5种IO的比较:

3.举例子
为了理解上面的理论,举例子如下:
陪女朋友逛街,逛累了,向找个地方吃饭,于是取了一个山西面馆,但是发现面馆生意比较好人比较多,而且面条都是先做的。但是这段时间又想干点别的事,比如去附近的书店看看书。于是引发了一些列的思考:
3.1 Blocking I/O
我不指定做面条需要多久,不敢出去,只能在那里坐在等。等做完,等服务员上面并且我吃调再走。
这里我们是应用线程,面条相当于等待读的数据,厨师相当于内核线程,我们需要等待初始做面条,还需要等待等服务员上面,我才能吃到我的面。
3.2 Nonblocking I/O
我不甘心在这里无聊的等待,我想在这段时间逛逛书店,但是又怕面条做好了,所有我决定取书店看一会书就回面馆看一下我的面是不是好了。如果没好继续取书店看会书再回面馆看看。结果就是来回跑了很多次。
3.3 I/O Multiplexing
我饭量比较大,同时在几个餐馆都点了饭菜,我这样来回来回看的话累死了,善良的管理员(管理所有餐馆)在前台装了一个大屏幕,上面写着每个人每个菜的状态。因此我虽然点了很多份饭菜,但只需要看屏幕就可以了。屏幕高速我某一个菜号了,我就可以去吃。
3.4 Signal Driven I/O
管理员看老是很多人来前台看状态,烦死了,于是弄来个喊号的系统,即每次有饭菜做好了,就会喊点菜的人来吃。但是,这个喊号的系统只会喊一次,并且如果同时多个菜好了,需要一个一个喊,因此部分饭菜有延时。
3.5 Asynchronous I/O
随着行业竞争加大,管理员为了提高用户体验,每次饭菜好了,让各个餐馆的服务员亲自将饭菜送到顾客的手上。
4.参考
http://www.yeolar.com/note/2012/12/15/high-performance-io-design-patterns/
http://www.cnblogs.com/zhuYears/archive/2012/09/28/2690194.html
http://yaocoder.blog.51cto.com/2668309/1308899
http://www.open-open.com/doc/view/cbb2c3363c3b49ceb5812220a9c42e42
http://www.ibm.com/developerworks/cn/linux/l-async/