在使用Unsafe之前,我们需要创建Unsafe对象的实例.这并不像Unsafe unsafe = new Unsafe()这么简单,因为Unsafe的构造器是私有的.它也有一个静态的getUnsafe()方法,但如果你直接调用Unsafe.getUnsafe(),你可能会得到SecurityException异常.只能从受信任的代码中使用这个方法:
public static Unsafe getUnsafe() {
Class cc = sun.reflect.Reflection.getCallerClass(2);
if (cc.getClassLoader() != null)
throw new SecurityException("Unsafe");
return theUnsafe;
}
classA{privatelonga;// not initialized value//构造器publicA(){this.a=1;// initialization}publiclonga(){returnthis.a;}}
使用构造器、反射和unsafe初始化它,将得到不同的结果.
12345678
Ao1=newA();// 构造器o1.a();// prints 1Ao2=A.class.newInstance();// 反射o2.a();// prints 1Ao3=(A)unsafe.allocateInstance(A.class);// unsafeo3.a();// prints 0
publicstaticlongsizeOf(Objecto){Unsafeu=getUnsafe();HashSet<Field>fields=newHashSet<Field>();Classc=o.getClass();while(c!=Object.class){for(Fieldf:c.getDeclaredFields()){if((f.getModifiers()&Modifier.STATIC)==0){fields.add(f);}}c=c.getSuperclass();}// get offsetlongmaxSize=0;for(Fieldf:fields){longoffset=u.objectFieldOffset(f);if(offset>maxSize){maxSize=offset;}}return((maxSize/8)+1)*8;// padding}
int NUM_OF_THREADS = 1000;
int NUM_OF_INCREMENTS = 100000;
ExecutorService service = Executors.newFixedThreadPool(NUM_OF_THREADS);
Counter counter = ... // creating instance of specific counter
long before = System.currentTimeMillis();
for (int i = 0; i < NUM_OF_THREADS; i++) {
service.submit(new CounterClient(counter, NUM_OF_INCREMENTS));
}
service.shutdown();
service.awaitTermination(1, TimeUnit.MINUTES);
long after = System.currentTimeMillis();
System.out.println("Counter result: " + c.getCounter());
System.out.println("Time passed in ms:" + (after - before));
/* An item in the connection queue. */typedefstructconn_queue_itemCQ_ITEM;structconn_queue_item{intsfd;enumconn_statesinit_state;intevent_flags;intread_buffer_size;enumnetwork_transporttransport;CQ_ITEM*next;};
CQ是一个管理CQ_ITEM的单向链表:
thread.c
1234567
/* A connection queue. */typedefstructconn_queueCQ;structconn_queue{CQ_ITEM*head;CQ_ITEM*tail;pthread_mutex_tlock;};
typedefstruct{pthread_tthread_id;/* unique ID of this thread */structevent_base*base;/* libevent handle this thread uses */structeventnotify_event;/* listen event for notify pipe */intnotify_receive_fd;/* receiving end of notify pipe */intnotify_send_fd;/* sending end of notify pipe */structthread_statsstats;/* Stats generated by this thread */structconn_queue*new_conn_queue;/* CQ队列 */cache_t*suffix_cache;/* suffix cache */uint8_titem_lock_type;/* use fine-grained or global item lock */}LIBEVENT_THREAD;
2.2主流程
在memcached.c的main函数中展示了客户端请求处理的主流程:
(1).对主线程的libevent做了初始化
12
/* initialize main thread libevent instance */main_base=event_init();
(2).初始化所有的线程(包括Master和Worker线程),并启动
12
/* start up worker threads if MT mode */thread_init(settings.num_threads,main_base);
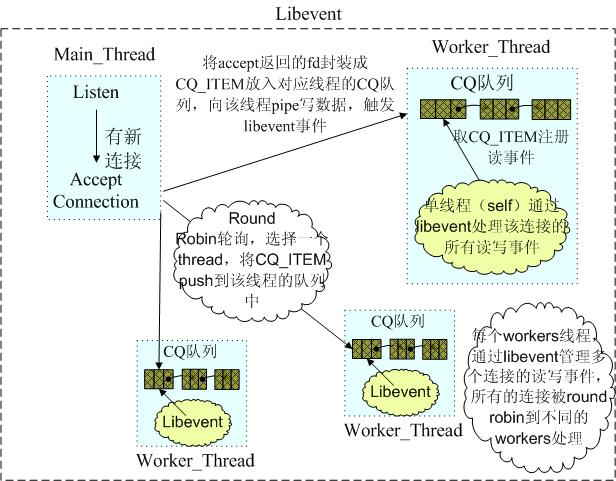
/* * Initializes the thread subsystem, creating various worker threads. * * nthreads Number of worker event handler threads to spawn * main_base Event base for main thread */voidthread_init(intnthreads,structevent_base*main_base){...//省略若干代码//threads的声明在thread.c头部,用于保存所有的线程threads=calloc(nthreads,sizeof(LIBEVENT_THREAD));if(!threads){perror("Can't allocate thread descriptors");exit(1);}dispatcher_thread.base=main_base;dispatcher_thread.thread_id=pthread_self();for(i=0;i<nthreads;i++){intfds[2];if(pipe(fds)){//创建管道perror("Can't create notify pipe");exit(1);}threads[i].notify_receive_fd=fds[0];//读端threads[i].notify_send_fd=fds[1];//写端//创建所有workers线程的libevent实例setup_thread(&threads[i]);/* Reserve three fds for the libevent base, and two for the pipe */stats.reserved_fds+=5;}//创建线程/* Create threads after we've done all the libevent setup. */for(i=0;i<nthreads;i++){create_worker(worker_libevent,&threads[i]);}//等待所有线程启动起来之后,这个函数再返回/* Wait for all the threads to set themselves up before returning. */pthread_mutex_lock(&init_lock);wait_for_thread_registration(nthreads);pthread_mutex_unlock(&init_lock);}
/* * Set up a thread's information. */staticvoidsetup_thread(LIBEVENT_THREAD*me){me->base=event_init();if(!me->base){fprintf(stderr,"Can't allocate event base\n");exit(1);}//注意这里只有notify_receive_fd,即读端口/* Listen for notifications from other threads */event_set(&me->notify_event,me->notify_receive_fd,EV_READ|EV_PERSIST,thread_libevent_process,me);event_base_set(me->base,&me->notify_event);if(event_add(&me->notify_event,0)==-1){fprintf(stderr,"Can't monitor libevent notify pipe\n");exit(1);}me->new_conn_queue=malloc(sizeof(structconn_queue));if(me->new_conn_queue==NULL){perror("Failed to allocate memory for connection queue");exit(EXIT_FAILURE);}cq_init(me->new_conn_queue);...}
/* * Processes an incoming "handle a new connection" item. This is called when * input arrives on the libevent wakeup pipe. */staticvoidthread_libevent_process(intfd,shortwhich,void*arg){LIBEVENT_THREAD*me=arg;CQ_ITEM*item;charbuf[1];//从管道中读数据if(read(fd,buf,1)!=1)if(settings.verbose>0)fprintf(stderr,"Can't read from libevent pipe\n");switch(buf[0]){case'c'://c表示有新的连接请求被主线程分配到当前Worker线程item=cq_pop(me->new_conn_queue);if(NULL!=item){conn*c=conn_new(item->sfd,item->init_state,item->event_flags,item->read_buffer_size,item->transport,me->base);if(c==NULL){if(IS_UDP(item->transport)){fprintf(stderr,"Can't listen for events on UDP socket\n");exit(1);}else{if(settings.verbose>0){fprintf(stderr,"Can't listen for events on fd %d\n",item->sfd);}close(item->sfd);}}else{c->thread=me;}cqi_free(item);}break;/* we were told to flip the lock type and report in */case'l':...case'g':...}}
/* * Worker thread: main event loop */staticvoid*worker_libevent(void*arg){LIBEVENT_THREAD*me=arg;/* Any per-thread setup can happen here; thread_init() will block until * all threads have finished initializing. *//* set an indexable thread-specific memory item for the lock type. * this could be unnecessary if we pass the conn *c struct through * all item_lock calls... */me->item_lock_type=ITEM_LOCK_GRANULAR;pthread_setspecific(item_lock_type_key,&me->item_lock_type);register_thread_initialized();event_base_loop(me->base,0);returnNULL;}
/** * Create a socket and bind it to a specific port number * @param interface the interface to bind to * @param port the port number to bind to * @param transport the transport protocol (TCP / UDP) * @param portnumber_file A filepointer to write the port numbers to * when they are successfully added to the list of ports we * listen on. */staticintserver_socket(constchar*interface,intport,enumnetwork_transporttransport,FILE*portnumber_file){...//省略若干代码//主机名到地址解析,结果存在ai中,为addrinfo的链表error=getaddrinfo(interface,port_buf,&hints,&ai);if(error!=0){if(error!=EAI_SYSTEM)fprintf(stderr,"getaddrinfo(): %s\n",gai_strerror(error));elseperror("getaddrinfo()");return1;}for(next=ai;next;next=next->ai_next){conn*listen_conn_add;if((sfd=new_socket(next))==-1){//创建socket/* getaddrinfo can return "junk" addresses, * we make sure at least one works before erroring. */if(errno==EMFILE){/* ...unless we're out of fds */perror("server_socket");exit(EX_OSERR);}continue;}//IPV4地址,设置socket选项setsockopt(sfd,SOL_SOCKET,SO_REUSEADDR,(void*)&flags,sizeof(flags));...//省略若干代码//socket和地址绑定if(bind(sfd,next->ai_addr,next->ai_addrlen)==-1){if(errno!=EADDRINUSE){perror("bind()");close(sfd);freeaddrinfo(ai);return1;}close(sfd);continue;}else{success++;...//省略若干代码}if(IS_UDP(transport)){...//省略若干代码}else{if(!(listen_conn_add=conn_new(sfd,conn_listening,EV_READ|EV_PERSIST,1,transport,main_base))){fprintf(stderr,"failed to create listening connection\n");exit(EXIT_FAILURE);}listen_conn_add->next=listen_conn;listen_conn=listen_conn_add;}}freeaddrinfo(ai);/* Return zero iff we detected no errors in starting up connections */returnsuccess==0;}
/* * Dispatches a new connection to another thread. This is only ever called * from the main thread, either during initialization (for UDP) or because * of an incoming connection. */voiddispatch_conn_new(intsfd,enumconn_statesinit_state,intevent_flags,intread_buffer_size,enumnetwork_transporttransport){CQ_ITEM*item=cqi_new();//新申请一个CQ_ITEMcharbuf[1];if(item==NULL){close(sfd);/* given that malloc failed this may also fail, but let's try */fprintf(stderr,"Failed to allocate memory for connection object\n");return;}//分发给Worker线程inttid=(last_thread+1)%settings.num_threads;LIBEVENT_THREAD*thread=threads+tid;last_thread=tid;item->sfd=sfd;item->init_state=init_state;//注意这里的状态为conn_new_cmditem->event_flags=event_flags;item->read_buffer_size=read_buffer_size;item->transport=transport;//把新申请的CQ_ITEM放到被分配的Worker线程的队列中cq_push(thread->new_conn_queue,item);MEMCACHED_CONN_DISPATCH(sfd,thread->thread_id);buf[0]='c';//向worker thread线程的管道写入一字节的数据if(write(thread->notify_send_fd,buf,1)!=1){perror("Writing to thread notify pipe");}}
/* * Processes an incoming "handle a new connection" item. This is called when * input arrives on the libevent wakeup pipe. */staticvoidthread_libevent_process(intfd,shortwhich,void*arg){LIBEVENT_THREAD*me=arg;CQ_ITEM*item;charbuf[1];//从管道中读数据if(read(fd,buf,1)!=1)if(settings.verbose>0)fprintf(stderr,"Can't read from libevent pipe\n");switch(buf[0]){case'c'://c表示有新的连接请求被主线程分配到当前Worker线程//从当前Worker线程的连接请求队列中弹出一个请求//此对象即先前main thread线程推入new_conn_queue队列的对象item=cq_pop(me->new_conn_queue);if(NULL!=item){//根据这个CQ_ITEM对象,创建并初始化conn对象//该对象负责客户端与该worker thread线程之间的通信conn*c=conn_new(item->sfd,item->init_state,item->event_flags,item->read_buffer_size,item->transport,me->base);if(c==NULL){if(IS_UDP(item->transport)){fprintf(stderr,"Can't listen for events on UDP socket\n");exit(1);}else{if(settings.verbose>0){fprintf(stderr,"Can't listen for events on fd %d\n",item->sfd);}close(item->sfd);}}else{c->thread=me;}cqi_free(item);}break;/* we were told to flip the lock type and report in */case'l':...case'g':...}}
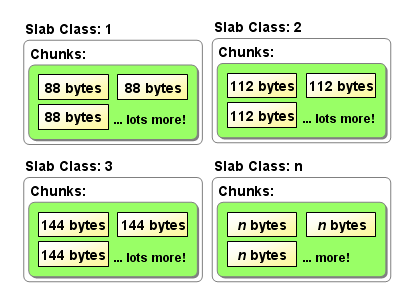
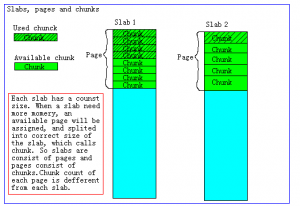
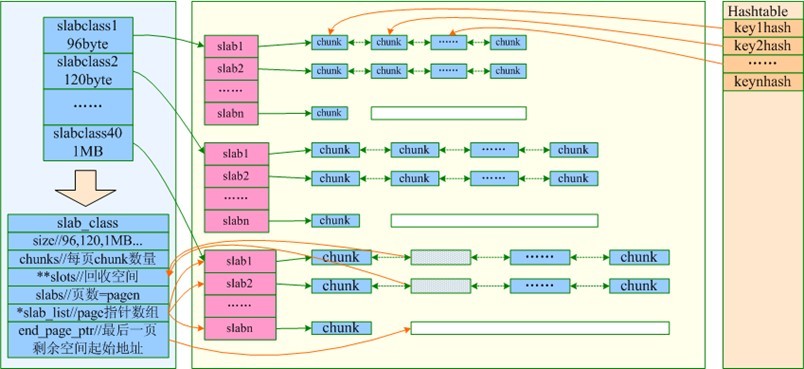
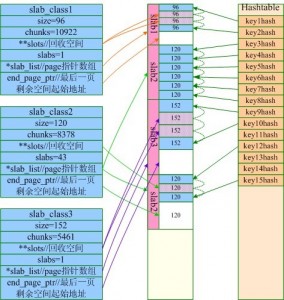
/** Init the subsystem. 1st argument is the limit on no. of bytes to allocate, 0 if no limit. 2nd argument is the growth factor; each slab will use a chunk size equal to the previous slab's chunk size times this factor. 3rd argument specifies if the slab allocator should allocate all memory up front (if true), or allocate memory in chunks as it is needed (if false)*/voidslabs_init(constsize_tlimit,constdoublefactor,constboolprealloc);
/** * Determines the chunk sizes and initializes the slab class descriptors * accordingly. */voidslabs_init(constsize_tlimit,constdoublefactor,constboolprealloc){inti=POWER_SMALLEST-1;//真实占用大小=对象大小+48unsignedintsize=sizeof(item)+settings.chunk_size;mem_limit=limit;//开启预分配,则首先将limit大小(默认64M)的内存全部申请if(prealloc){/* Allocate everything in a big chunk with malloc */mem_base=malloc(mem_limit);if(mem_base!=NULL){mem_current=mem_base;mem_avail=mem_limit;}else{fprintf(stderr,"Warning: Failed to allocate requested memory in"" one large chunk.\nWill allocate in smaller chunks\n");}}//清空所有的slabmemset(slabclass,0,sizeof(slabclass));while(++i<POWER_LARGEST&&size<=settings.item_size_max/factor){/* Make sure items are always n-byte aligned */if(size%CHUNK_ALIGN_BYTES)size+=CHUNK_ALIGN_BYTES-(size%CHUNK_ALIGN_BYTES);slabclass[i].size=size;slabclass[i].perslab=settings.item_size_max/slabclass[i].size;size*=factor;if(settings.verbose>1){fprintf(stderr,"slab class %3d: chunk size %9u perslab %7u\n",i,slabclass[i].size,slabclass[i].perslab);}}//最大chunksize的一个slab,chunksize为settings.item_size_max(默认1M)power_largest=i;slabclass[power_largest].size=settings.item_size_max;slabclass[power_largest].perslab=1;if(settings.verbose>1){fprintf(stderr,"slab class %3d: chunk size %9u perslab %7u\n",i,slabclass[i].size,slabclass[i].perslab);}//记录已分配的空间大小/* for the test suite: faking of how much we've already malloc'd */{char*t_initial_malloc=getenv("T_MEMD_INITIAL_MALLOC");if(t_initial_malloc){mem_malloced=(size_t)atol(t_initial_malloc);}}//开启了预分配,则为每种slab都分配一个page的空间if(prealloc){slabs_preallocate(power_largest);}}
其中settings.chunk_size默认为48:
settings.chunk_size = 48; /* space for a modest key and value */
staticvoidslabs_preallocate(constunsignedintmaxslabs){inti;unsignedintprealloc=0;/* pre-allocate a 1MB slab in every size class so people don't get confused by non-intuitive "SERVER_ERROR out of memory" messages. this is the most common question on the mailing list. if you really don't want this, you can rebuild without these three lines. */for(i=POWER_SMALLEST;i<=POWER_LARGEST;i++){if(++prealloc>maxslabs)return;if(do_slabs_newslab(i)==0){fprintf(stderr,"Error while preallocating slab memory!\n""If using -L or other prealloc options, max memory must be ""at least %d megabytes.\n",power_largest);exit(1);}}}
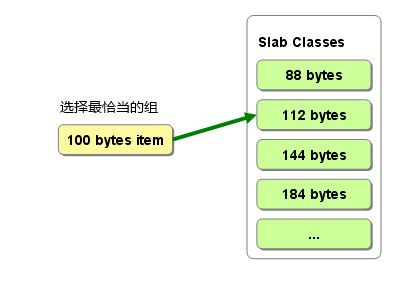
/* * Figures out which slab class (chunk size) is required to store an item of * a given size. * * Given object size, return id to use when allocating/freeing memory for object * 0 means error: can't store such a large object */unsignedintslabs_clsid(constsize_tsize){intres=POWER_SMALLEST;//最小slab编号if(size==0)return0;while(size>slabclass[res].size)if(res++==power_largest)/* won't fit in the biggest slab */return0;returnres;}
perlmemcached-tool10.0.0.5:11211display#showsslabsperlmemcached-tool10.0.0.5:11211#same.(defaultisdisplay)perlmemcached-tool10.0.0.5:11211stats#showsgeneralstatsperlmemcached-tool10.0.0.5:11211move79#takes1MBslabfromclass#7# to class #9.
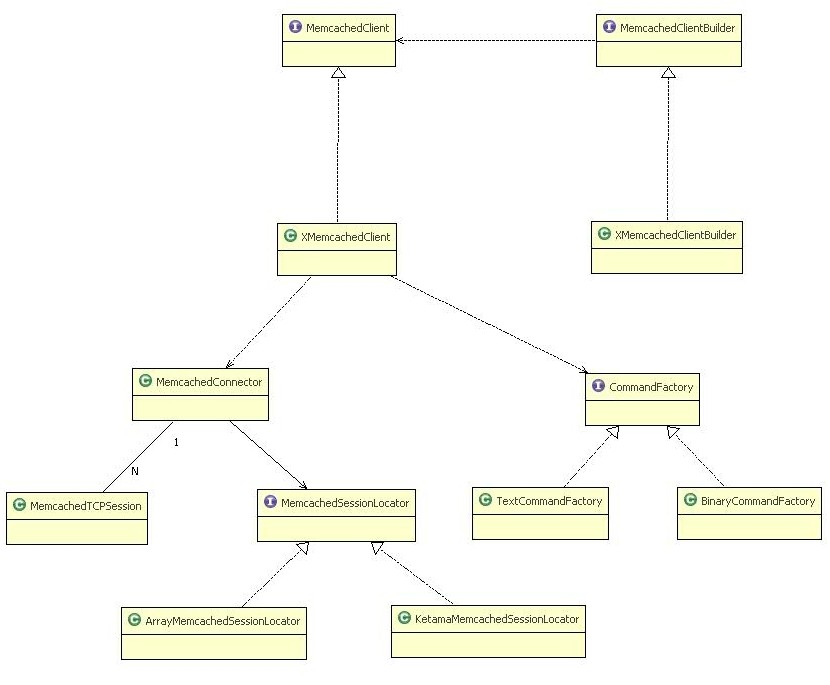
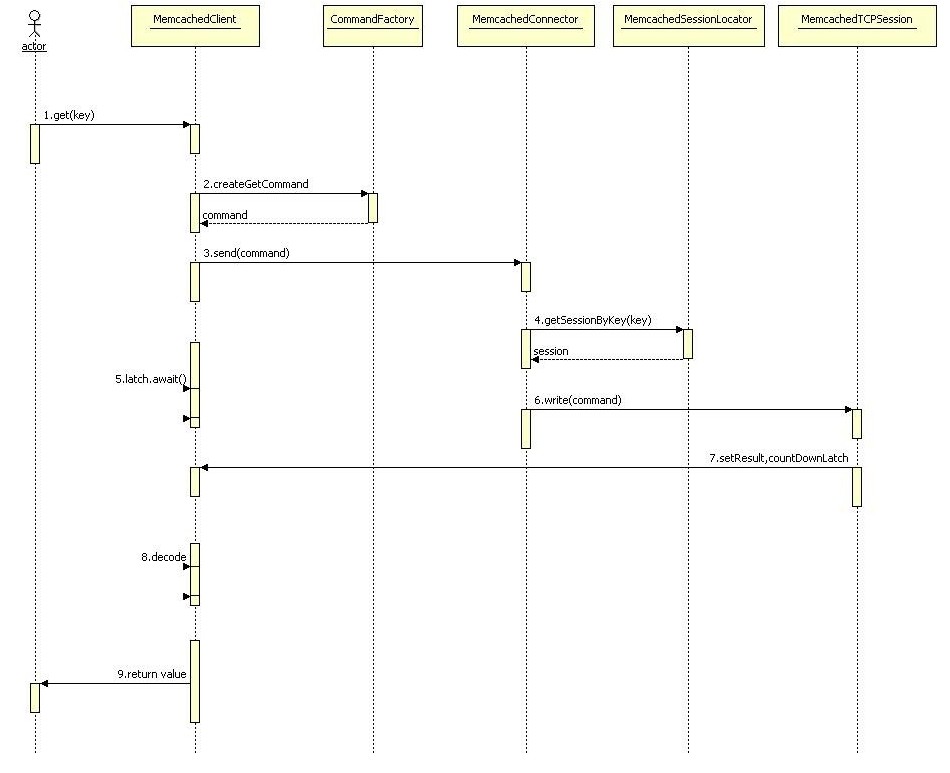
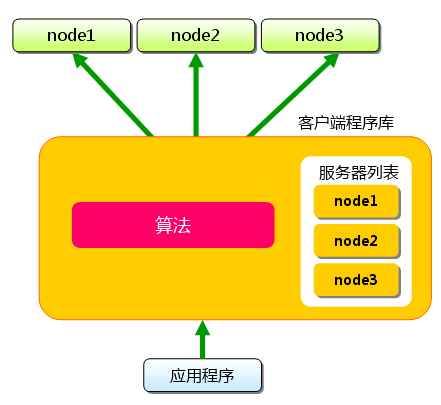
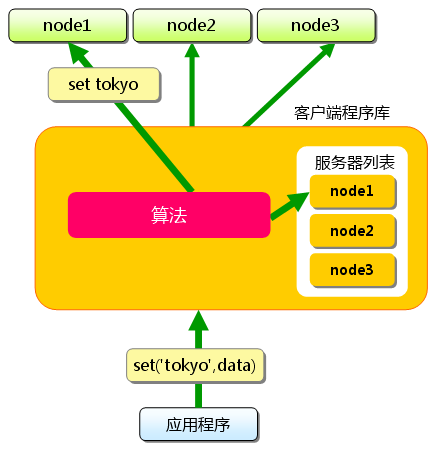
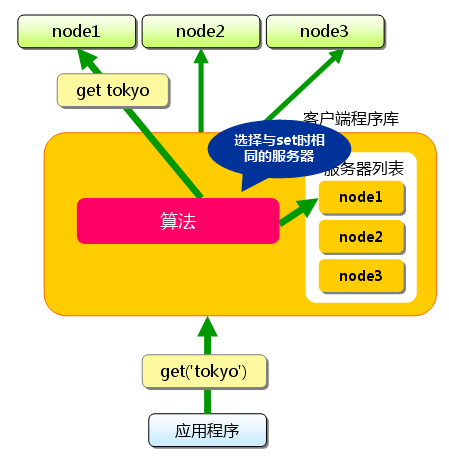
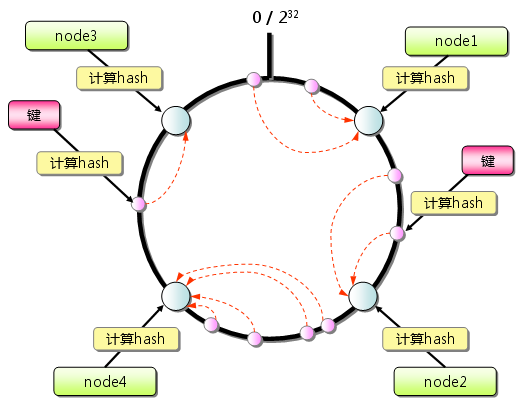
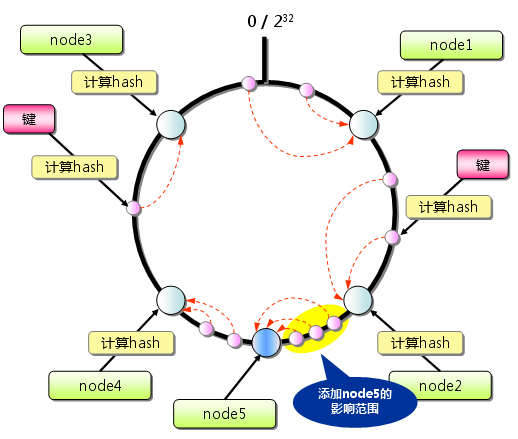
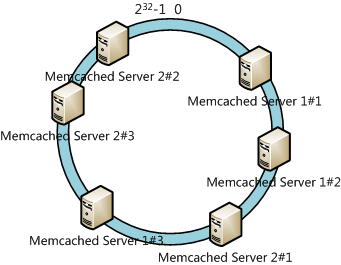
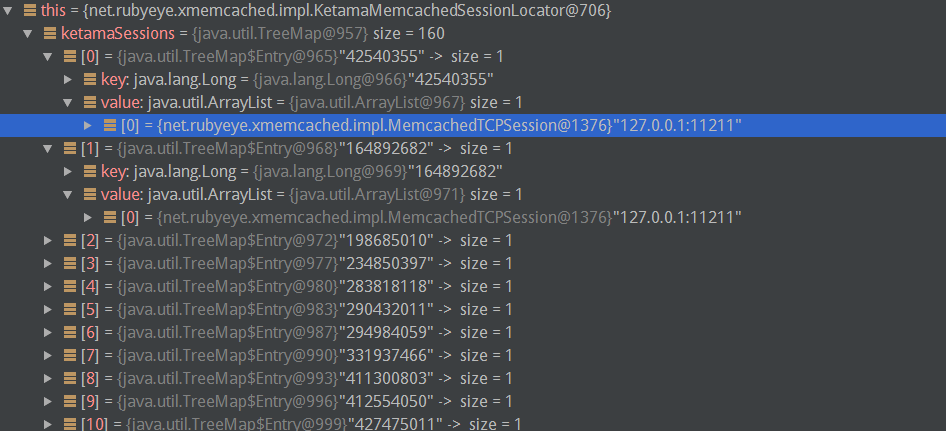 4.4.2 对Key做Hash
4.4.2 对Key做Hash getSessionByHash的逻辑其实就是在Hash环上找第一个大于key对应hash值的虚拟节点,通过虚拟节点找到真实服务器.
getSessionByHash的逻辑其实就是在Hash环上找第一个大于key对应hash值的虚拟节点,通过虚拟节点找到真实服务器.