bc 的特殊变量 ibase 和 obase 分别包含用于输入和输出的进制的值.缺省情况下,都被设置为 10.要执行进制转换,需要改变其中的一个或两个值,然后提供一个数字.
123456
xiaobaoqiu@xiaobaoqiu:~/myshell$ echo 'obase=16; 10' | bc
A
xiaobaoqiu@xiaobaoqiu:~/myshell$ echo 'obase=16; ibase=10; 10' | bc
A
xiaobaoqiu@xiaobaoqiu:~/myshell$ echo 'obase=10; ibase=16; 10' | bc
16
double rate; // leak rate in calls/s
double burst; // bucket size in calls
long refreshTime; // time for last water refresh
double water; // water count at refreshTime
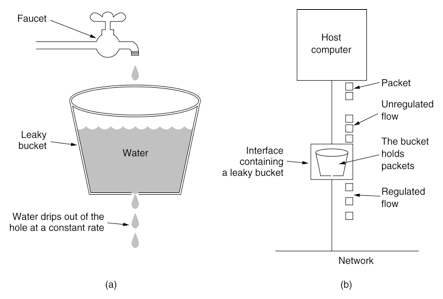
refreshWater() {
long now = getTimeOfDay();
//水随着时间流逝,不断流走,最多就流干到0.
water = max(0, water- (now - refreshTime)*rate);
refreshTime = now;
}
bool permissionGranted() {
refreshWater();
if (water < burst) { // 水桶还没满,继续加1
water ++;
return true;
} else {
return false;
}
}
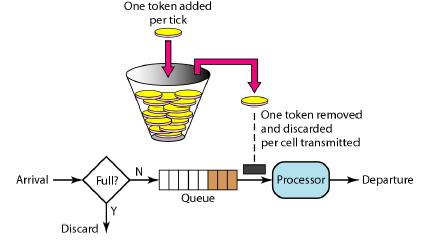
public double acquire();
public double acquire(int permits);
尝试获取令牌,分为待超时时间和不带超时时间两种:
123456
public boolean tryAcquire();
//尝试获取一个令牌,立即返回
public boolean tryAcquire(int permits);
public boolean tryAcquire(long timeout, TimeUnit unit);
//尝试获取permits个令牌,带超时时间
public boolean tryAcquire(int permits, long timeout, TimeUnit unit);
过去一段时间的利用不足意味着有过剩的资源是可以利用的.这种情况下,RateLimiter应该加把劲(speed up for a while)将这些过剩的资源利用起来.比如在向网络中发生数据的场景(限流),过去一段时间的利用不足可能意味着网卡缓冲区是空的,这种场景下,我们是可以加速发送来将这些过程的资源利用起来.
另一方面,过去一段时间的利用不足可能意味着处理请求的服务器对即将到来的请求是准备不足的(less ready for future requests),比如因为很长一段时间没有请求当前服务器的cache是陈旧的,进而导致即将到来的请求会触发一个昂贵的操作(比如重新刷新全量的缓存).
/**
* Translates a specified portion of our currently stored permits which we want to
* spend/acquire, into a throttling time. Conceptually, this evaluates the integral
* of the underlying function we use, for the range of
* [(storedPermits - permitsToTake), storedPermits].
*
* <p>This always holds: {@code 0 <= permitsToTake <= storedPermits}
*/
abstract long storedPermitsToWaitTime(double storedPermits, double permitsToTake);
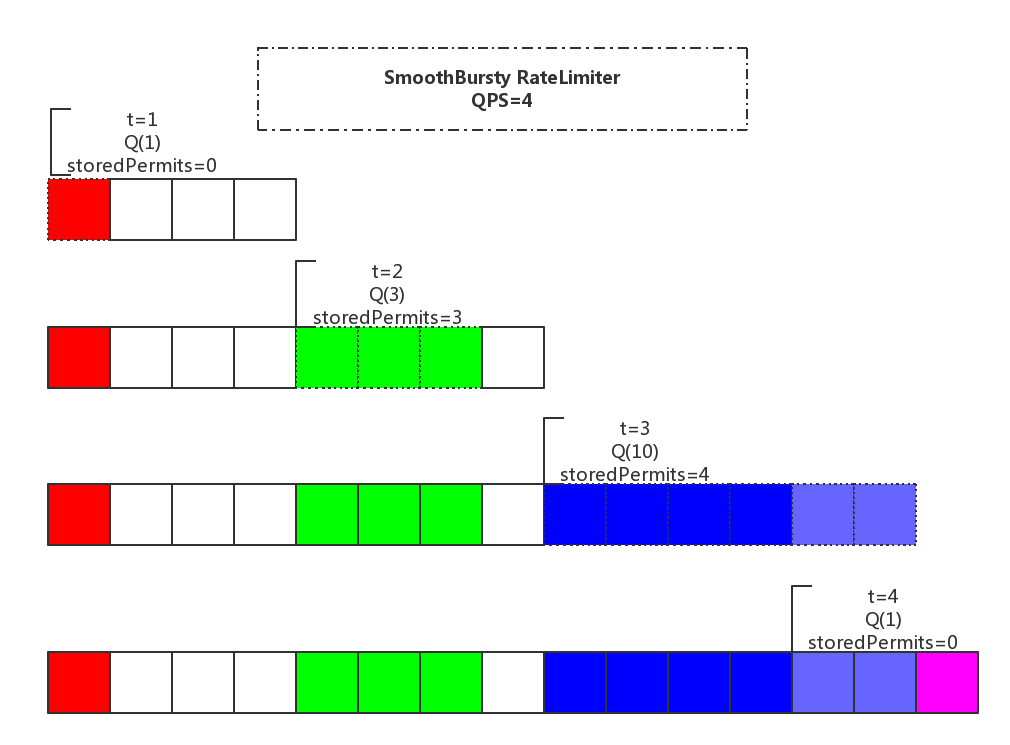
/**
* This implements a "bursty" RateLimiter, where storedPermits are translated to
* zero throttling. The maximum number of permits that can be saved (when the RateLimiter is
* unused) is defined in terms of time, in this sense: if a RateLimiter is 2qps, and this
* time is specified as 10 seconds, we can save up to 2 * 10 = 20 permits.
*/
static final class SmoothBursty extends SmoothRateLimiter {
/** The work (permits) of how many seconds can be saved up if this RateLimiter is unused? */
final double maxBurstSeconds;
SmoothBursty(SleepingStopwatch stopwatch, double maxBurstSeconds) {
super(stopwatch);
this.maxBurstSeconds = maxBurstSeconds;
}
void doSetRate(double permitsPerSecond, double stableIntervalMicros) {
double oldMaxPermits = this.maxPermits;
maxPermits = maxBurstSeconds * permitsPerSecond;
System.out.println("maxPermits=" + maxPermits);
if (oldMaxPermits == Double.POSITIVE_INFINITY) {
// if we don't special-case this, we would get storedPermits == NaN, below
storedPermits = maxPermits;
} else {
storedPermits = (oldMaxPermits == 0.0)
? 0.0 // initial state
: storedPermits * maxPermits / oldMaxPermits;
}
}
long storedPermitsToWaitTime(double storedPermits, double permitsToTake) {
return 0L;
}
}
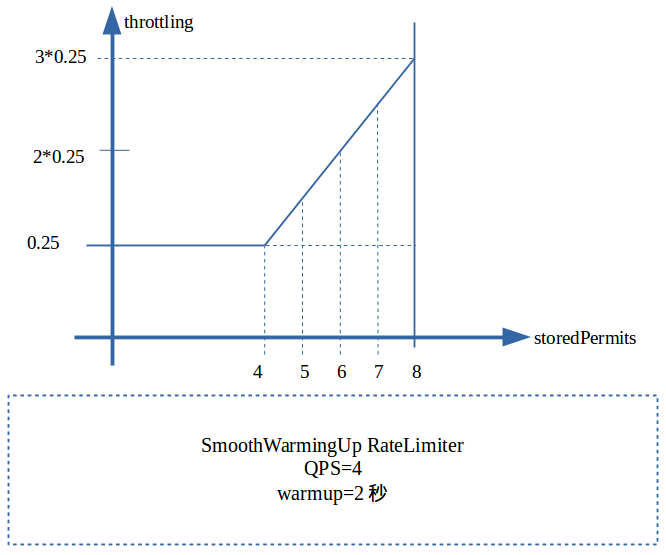
static final class SmoothWarmingUp extends SmoothRateLimiter {
private final long warmupPeriodMicros;
/**
* The slope of the line from the stable interval (when permits == 0), to the cold interval
* (when permits == maxPermits)
*/
private double slope;
private double halfPermits;
SmoothWarmingUp(SleepingStopwatch stopwatch, long warmupPeriod, TimeUnit timeUnit) {
super(stopwatch);
this.warmupPeriodMicros = timeUnit.toMicros(warmupPeriod);
}
@Override
void doSetRate(double permitsPerSecond, double stableIntervalMicros) {
double oldMaxPermits = maxPermits;
maxPermits = warmupPeriodMicros / stableIntervalMicros;
halfPermits = maxPermits / 2.0;
// Stable interval is x, cold is 3x, so on average it's 2x. Double the time -> halve the rate
double coldIntervalMicros = stableIntervalMicros * 3.0;
slope = (coldIntervalMicros - stableIntervalMicros) / halfPermits;
if (oldMaxPermits == Double.POSITIVE_INFINITY) {
// if we don't special-case this, we would get storedPermits == NaN, below
storedPermits = 0.0;
} else {
storedPermits = (oldMaxPermits == 0.0)
? maxPermits // initial state is cold
: storedPermits * maxPermits / oldMaxPermits;
}
}
@Override
long storedPermitsToWaitTime(double storedPermits, double permitsToTake) {
double availablePermitsAboveHalf = storedPermits - halfPermits;
long micros = 0;
// measuring the integral on the right part of the function (the climbing line)
if (availablePermitsAboveHalf > 0.0) {
double permitsAboveHalfToTake = min(availablePermitsAboveHalf, permitsToTake);
micros = (long) (permitsAboveHalfToTake * (permitsToTime(availablePermitsAboveHalf)
+ permitsToTime(availablePermitsAboveHalf - permitsAboveHalfToTake)) / 2.0);
permitsToTake -= permitsAboveHalfToTake;
}
// measuring the integral on the left part of the function (the horizontal line)
micros += (stableIntervalMicros * permitsToTake);
return micros;
}
private double permitsToTime(double permits) {
return stableIntervalMicros + permits * slope;
}
}
1.重启吃swap的服务,比如重启一下我们的java进程;
2.swapoff + swapon
这个方法的好处是,不用重启服务,但是需要确保现在有足够的物理内存可以容下从swap中释放出来的数据。下面给出了swapoff和swapon的具体做法,注意看swapoff后和swapon后,free的输出有什么异同;
sudo /sbin/swapoff -a
sudo /sbin/swapon -a
swapoff后,free的输出里,swap分区的大小变为0,占用变为0,也就是说swap分区中的数据已经释放到物理内存中,同时swap分区被禁用。swapon后,free的输出里,swap分区的容量又恢复了
,也就是说swap分区重新被启用了。当然我们可以把这两个命令写到一起:
sudo /sbin/swapoff -a && sudo /sbin/swapon -a
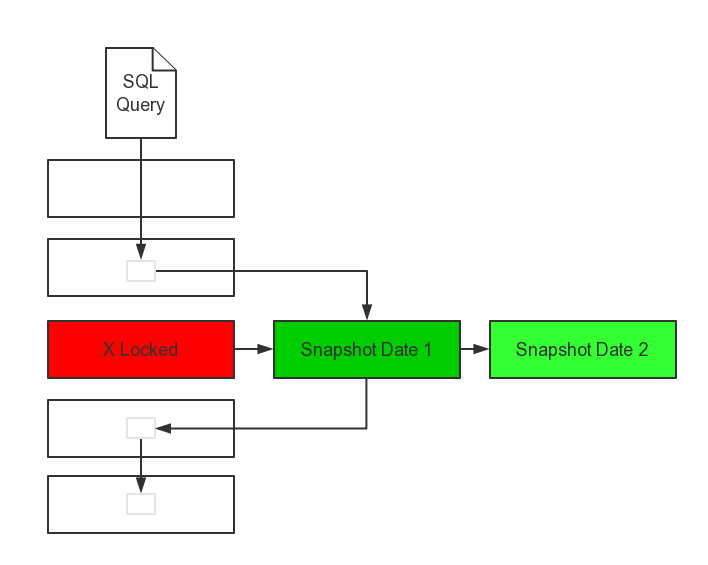
1.快照读(snapshot read或者consistent read)
快照读,读取的是记录的可见版本(有可能是历史版本),不用加锁;
通常,简单的select操作,属于快照读,不加锁,比如:
```
select * from table where ?
```
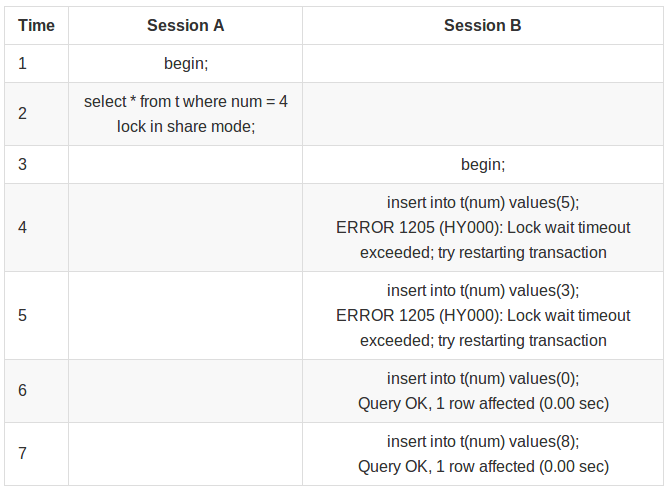
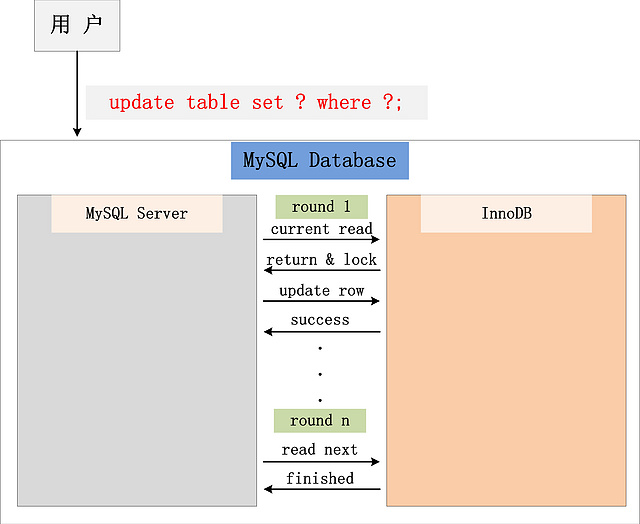
2.当前读(current read或者lock read)
当前读,读取的是记录的最新版本,并且,当前读返回的记录,都会加上锁,保证其他事务不会再并发修改这条记录.
特殊的读操作,插入/更新/删除操作,属于当前读,需要加锁.比如:
```
select * from table where ? lock in share mode
select * from table where ? for update
insert into table values (…)
update table set ? where ?
delete from table where ?
```
所有以上的语句,都属于当前读,读取记录的最新版本.并且,读取之后,还需要保证其他并发事务不能修改当前记录,对读取记录加锁.其中,除了第一条语句,对读取记录加S锁 (共享锁)外,其他的操作,都加的是X锁(排它锁).
mysql> SELECT @@session.tx_isolation;
+------------------------+
| @@session.tx_isolation |
+------------------------+
| READ-COMMITTED |
+------------------------+
mysql> select * from parent where id = 1;
+----+
| id |
+----+
| 1 |
+----+
那么,InnoDB指出的可以避免幻读是怎么回事呢?
http://dev.mysql.com/doc/refman/5.6/en/innodb-record-level-locks.html
By default, InnoDB operates in REPEATABLE READ transaction isolation level and with the innodb_locks_unsafe_for_binlog system variable disabled. In this case, InnoDB uses next-key locks for searches and index scans, which prevents phantom rows (see Section 13.6.8.5, “Avoiding the Phantom Problem Using Next-Key Locking”).
http://dev.mysql.com/doc/refman/5.6/en/innodb-next-key-locking.html
Avoiding the Phantom Problem Using Next-Key Locking
To prevent phantoms, InnoDB uses an algorithm called next-key locking that combines index-row locking with gap locking.
You can use next-key locking to implement a uniqueness check in your application: If you read your data in share mode and do not see a duplicate for a row you are going to insert, then you can safely insert your row and know that the next-key lock set on the successor of your row during the read prevents anyone meanwhile inserting a duplicate for your row. Thus, the next-key locking enables you to “lock” the nonexistence of something in your table.