[2015-05-14 15:50:51 ERROR com.alibaba.druid.pool.DruidDataSource:1363] create connection error
com.mysql.jdbc.exceptions.jdbc4.CommunicationsException: Communications link failure
The last packet sent successfully to the server was 0 milliseconds ago. The driver has not received any packets from the server.
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method) ~[na:1.7.0_45]
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:57) ~[na:1.7.0_45]
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45) ~[na:1.7.0_45]
at java.lang.reflect.Constructor.newInstance(Constructor.java:526) ~[na:1.7.0_45]
at com.mysql.jdbc.Util.handleNewInstance(Util.java:411) ~[mysql-connector-java-5.1.21.jar:na]
at com.mysql.jdbc.SQLError.createCommunicationsException(SQLError.java:1117) ~[mysql-connector-java-5.1.21.jar:na]
at com.mysql.jdbc.MysqlIO.<init>(MysqlIO.java:350) ~[mysql-connector-java-5.1.21.jar:na]
at com.mysql.jdbc.ConnectionImpl.coreConnect(ConnectionImpl.java:2393) ~[mysql-connector-java-5.1.21.jar:na]
at com.mysql.jdbc.ConnectionImpl.connectOneTryOnly(ConnectionImpl.java:2430) ~[mysql-connector-java-5.1.21.jar:na]
at com.mysql.jdbc.ConnectionImpl.createNewIO(ConnectionImpl.java:2215) ~[mysql-connector-java-5.1.21.jar:na]
at com.mysql.jdbc.ConnectionImpl.<init>(ConnectionImpl.java:813) ~[mysql-connector-java-5.1.21.jar:na]
at com.mysql.jdbc.JDBC4Connection.<init>(JDBC4Connection.java:47) ~[mysql-connector-java-5.1.21.jar:na]
at sun.reflect.GeneratedConstructorAccessor34.newInstance(Unknown Source) ~[na:na]
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45) ~[na:1.7.0_45]
at java.lang.reflect.Constructor.newInstance(Constructor.java:526) ~[na:1.7.0_45]
at com.mysql.jdbc.Util.handleNewInstance(Util.java:411) ~[mysql-connector-java-5.1.21.jar:na]
at com.mysql.jdbc.ConnectionImpl.getInstance(ConnectionImpl.java:399) ~[mysql-connector-java-5.1.21.jar:na]
at com.mysql.jdbc.NonRegisteringDriver.connect(NonRegisteringDriver.java:334) ~[mysql-connector-java-5.1.21.jar:na]
at com.alibaba.druid.pool.DruidAbstractDataSource.createPhysicalConnection(DruidAbstractDataSource.java:1296) ~[druid-0.2.18.jar:0.2.18]
at com.alibaba.druid.pool.DruidAbstractDataSource.createPhysicalConnection(DruidAbstractDataSource.java:1352) ~[druid-0.2.18.jar:0.2.18]
at com.alibaba.druid.pool.DruidDataSource$CreateConnectionThread.run(DruidDataSource.java:1361) ~[druid-0.2.18.jar:0.2.18]
Caused by: java.net.ConnectException: Connection refused
at java.net.PlainSocketImpl.socketConnect(Native Method) ~[na:1.7.0_45]
at java.net.AbstractPlainSocketImpl.doConnect(AbstractPlainSocketImpl.java:339) ~[na:1.7.0_45]
at java.net.AbstractPlainSocketImpl.connectToAddress(AbstractPlainSocketImpl.java:200) ~[na:1.7.0_45]
at java.net.AbstractPlainSocketImpl.connect(AbstractPlainSocketImpl.java:182) ~[na:1.7.0_45]
at java.net.SocksSocketImpl.connect(SocksSocketImpl.java:392) ~[na:1.7.0_45]
at java.net.Socket.connect(Socket.java:579) ~[na:1.7.0_45]
at java.net.Socket.connect(Socket.java:528) ~[na:1.7.0_45]
at java.net.Socket.<init>(Socket.java:425) ~[na:1.7.0_45]
at java.net.Socket.<init>(Socket.java:241) ~[na:1.7.0_45]
at com.mysql.jdbc.StandardSocketFactory.connect(StandardSocketFactory.java:257) ~[mysql-connector-java-5.1.21.jar:na]
at com.mysql.jdbc.MysqlIO.<init>(MysqlIO.java:300) ~[mysql-connector-java-5.1.21.jar:na]
... 14 common frames omitted
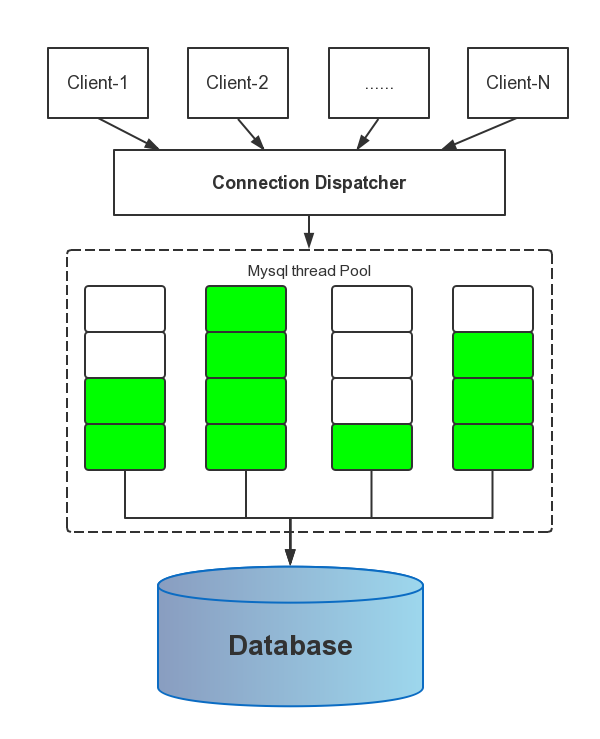
thread_pool_size is the most important parameter controlling thread pool performance. It can be set only at server startup. Our experience in testing the thread pool indicates the following:
If the primary storage engine is InnoDB, the optimal thread_pool_size setting is likely to be between 16 and 36, with the most common optimal values tending to be from 24 to 36. We have not seen any situation where the setting has been optimal beyond 36. There may be special cases where a value smaller than 16 is optimal.
For workloads such as DBT2 and Sysbench, the optimum for InnoDB seems to be usually around 36. For very write-intensive workloads, the optimal setting can sometimes be lower.
If the primary storage engine is MyISAM, the thread_pool_size setting should be fairly low. We tend to get optimal performance for values from 4 to 8. Higher values tend to have a slightly negative but not dramatic impact on performance.
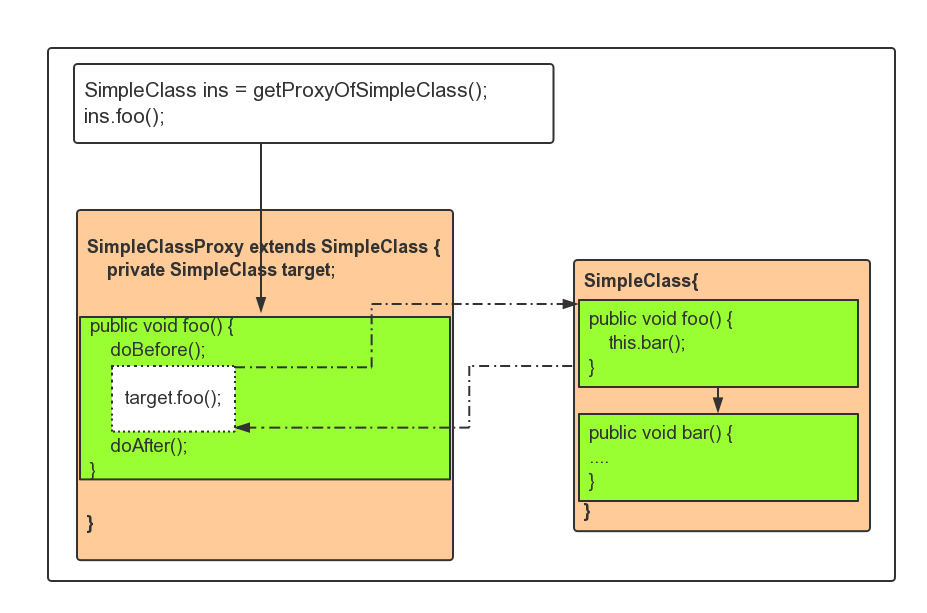
public class SimplePojo implements SimpleInterface {
public void foo() {
// this next method invocation is a direct call on the 'this' reference
this.bar();
}
public void bar() {
// some logic...
}
}
当你调用一个对象引用的方法时,此对象引用上的方法直接被调用,如下所示:
12345
public static void main(String[] args) {
SimplePojo ins = new SimplePojo();
// this is a direct method call on the 'ins' reference
ins.foo();
}
#!/bin/bash
if echo $1 | grep -q "/home/q/crate_workspace"
then
export CRATE_BASE=${1%/}
else
export CRATE_BASE=/home/q/crate_workspace/${1%/}
fi
echo -e $CRATE_BASE
if ! [ -e $CRATE_BASE/crate-source/bin/crate ]
then
echo -e " usage: $0 home/q/crate_workspace/CRATE_DIR\n"
exit 1;
fi
if ! [ -e $CRATE_BASE/pid ]
then
echo "crate instance not found : ${1%/}";
exit;
fi
CRATE_ID=`cat $CRATE_BASE/pid`
for i in {1..10}; do
if [ -e $CRATE_BASE/pid ]; then
CRATE_ID=`cat $CRATE_BASE/pid`
if [ "$i" = "1" ]; then
echo -n "trying stop ($CRATE_ID): $i"
else
echo -n -e "\b$i"
fi
if [ $i -ge 5 ]; then
kill "$CRATE_ID"
rm -f "$CRATE_BASE/pid"
fi
sleep 1
else
if [ $i -gt 5 ]; then
echo -e "\n$CRATE_BASE was killed($i)"
else
echo -e "\n$CRATE_BASE was stoped"
fi
exit;
fi
done;
kill -9 "$CRATE_ID"
echo "$CRATE_BASE was force killed"
dubbo>cd Xxx.xx.xxx.service.ConsumerMessageHandler
Used the Xxx.xx.xxx.service.ConsumerMessageHandler as default.
You can cancel default service by command: cd /
5.pwd
显示当前缺省服务
12345678
dubbo>pwd
Xxx.xx.xxx.service.ConsumerMessageHandler
dubbo>cd /
Cancelled default service qunar.tc.qmq.service.ConsumerMessageHandler.
dubbo>pwd
/
dubbo>help
Please input "help [command]" show detail.
log level - Change log level or show log
pwd - Print working default service.
trace [service] [method] [times] - Trace the service.
clear [lines] - Clear screen.
exit - Exit the telnet.
help [command] - Show help.
info - show dubbo info
ls [-l] [service] - List services and methods.
invoke [service.]method(args) - Invoke the service method.
ps [-l] [port] - Print server ports and connections.
cd [service] - Change default service.
status [-l] - Show status.
count [service] [method] [times] - Count the service.
public static void test2_3(){
int result1 = parser.parseExpression("1+2-3*4/2").getValue(Integer.class);
int result2 = parser.parseExpression("4%3").getValue(Integer.class);
int result3 = parser.parseExpression("2^3").getValue(Integer.class);
}